|
|
|
|
2007.02.10
カテゴリ:C言語
前回の内容は結果的に数学的な分野のプログラムを書きたい人ぐらいにしか
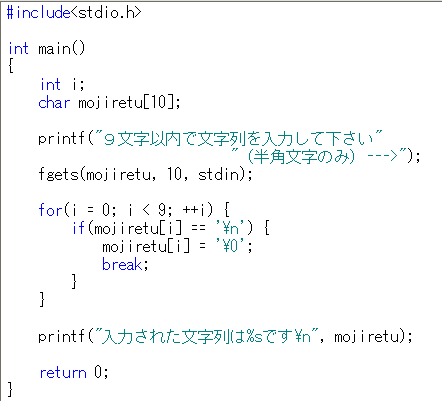
役に立ってませんでしたね…。 しかし、今回の内容は誰にでも役に立つはずです。 「文字列関数」 これは文字列を操作したい時に非常に役に立ってくれます。 文字列の操作は色々な分野で使われるはずなので前回よりは頑張って覚えてください^^; <string.h><string.h>にはかなりの量の文字列操作関数がありますが、今回紹介するのは そのうちの4つだけです。とはいえ、4つでも結構覚えるのは大変ですが…。 まず1つ目は文字列を別の文字配列にコピーする「strncpy」です。 数値のように b = a;として代入できればいいのですが 残念ながら文字列は上記のような代入はできません。 そのためstrncpyというものがあります。 私はプログラミングの授業ではstrcpyというのを習いましたが MicrosoftのHPで調べてみた限りではstrcpyはバグを引き起こす可能性があるとのことだったので ここではstrncpyを紹介します。strncpyとstrcpyの違いは文字の長さの制限が出来るかできないか です。 これはfgets関数を使用したほうがいい理由と同じなので当サイトではstrncpyを使います。 2007/2/20にstrncpyの危険性を知ったので修正をします。 strncpy関数の例では、この関数を使った例を紹介します。 それと同時にこの関数を使わずに文字列をコピーする方法も紹介します。 そうすればstrncpyを使った方が楽だという事が分かり易いですしね。  まず最初に2行目で<string.h>をインクルードしています。これはもういいですね。 そして9行目で文字配列a,b,cを宣言しています。aには"test"という文字列を格納しています。 いよいよ肝心のコピーです。 10行目でstrncpy(b, a, sizeof(b) - 1); 13行目でb[sizeof(b) - 1] = '\0';としていますね。 これがstrncpyの使い方です。 1つ目の引数の文字配列に2つ目の引数の文字配列を 3つ目の引数の数値分-1だけコピーをする ということになります。 この例ではbにaの内容をsizeof(b) - 1、すなわち9文字分コピーする事になります。 つまりb[10],a[20]でaには10文字以上が格納されていたとしても bにはaの最初の9文字分しかコピーされません。 一見いいように思えないかもしれませんが それ以上コピーされてしまうとバグが起きる可能性が非常に高くなります…。 ここでstrcpy関数だとb[10]なのに、10文字以上を平然とコピーしてしまうのでこれが危険なわけです。 何故ここでsizeof(b) - 1のように1を引いているかですが、これは 配列の最後には'\0'を入れなければいけないためです。 これがないとprintf関数で出力する際にエラーが起きることになります。 そして、一応for文を使って1文字ずつコピーするという方法も例に載せました。 strncpyの処理内容をあえて再現しようとすると大体こんな感じになるはずです。 どう見てもstrncpyの方が簡単ですね。 さて、次は2つ目としてstrlen関数を紹介します。 strlen関数の紹介と例strlen関数は文字列の長さを求める関数です。 この関数は結構便利です。 まぁこの関数を使わないで同じ処理を作るのも容易ですが…。 早速strlen関数の使用例と同じ処理の例を紹介します。  strlen関数の引数は長さを知りたい配列1つだけです。実に簡単ですね。 9行目でprintf("%d\n", strlen(a));として、文字列の長さを出力しています。 ここでの文字列の長さというのは'\0'(ヌル文字)を含みません。 これが重要になることもありますので頭の片隅辺りにでも残して置いて下さい^^; そして、同じ処理はfor文で1文字ずつヌル文字かどうかを比較します。 ヌル文字があった場合はそこのiの値をlengthに代入します。 これだとヌル文字も含んでいるわけですが そもそもiの最初の値は0だったわけなのでちょうどズレが無くなります。 事実今回の例の文字列の長さは26なのですが、ぴったり26になりますから。 何だかこの処理似たのをどっかで見たことがある気がしませんか? それはこれです。 この時はfgets関数が改行文字を削除しないという点に対して改行文字を探していました。 今回はヌル文字を探していたわけなので、まぁ似てるといえば似てる気がしますね。 この改行文字削除の方法を書いている時に 私は「CMAGAZINE」で紹介されていた対処法がどうこう言っていました。 実はこの対処法というのはこのstrlen関数を使う方法だったわけです。 strlen関数を使ってfgets関数の改行文字削除のプログラム例を紹介します。  流石にそのまま引用するのも不味いので簡略化しました。一応引用元:CMAGAZINE 2005年11月号 と引用元を明記しておきます。 これだとわざわざfor文でループする必要は無いわけです。 これはかなり便利だと思われます。ちなみにstrlen(mojiretu)の値は配列でいうとちょうどヌル文字の位置になります。 先ほどのforループでやったstrlen関数と同じ処理の内容でも触れましたね。 そのため、その1つ前の文字が入力された最後の文字なわけです。 ただ、この状況だと9文字の入力の場合は10文字目の改行文字はfgets関数の性質で無視されます。 そのため、if文で本当にstrlen(mojiretu) - 1が改行文字なのかをチェックしています。 この処理を忘れると9文字目が消えてしまいますので(ちなみに私はついさっきそれをやりましたorz) まぁ結局strlen関数を使っても前の例のようにforループを使っても問題はないので 自分が楽だと思う方で改行文字を削除していけばいいかと思います。 さて、次は3つ目としてstrncat関数を紹介します。 2007/2/20にstrncatの危険性を知ったので修正をします。 strncat関数の紹介と例strncat関数は文字列と文字列を結合することができる関数です。 これにもstrcat関数というのがありますが、strcpy関数と同じ理由でこのサイトではstrncatを使います。 これも当然strncpyの時のようにstrncat関数を使用しないでも同じ処理を実現する事はできます。 しかし、今回はstrncpyの時より面倒です。 なのでできればstrncat関数の方を覚えた方がいいと思います。 では、strncatの例を紹介します。  まず9行目ではstrncat関数を使用しています。この関数は1つ目の引数の文字配列に 2つ目の引数の文字配列の内容を結合します。結合する文字数は3つ目の引数の数値分です。 この3つ目の引数では先ほどやったばかりのstrlen関数を使用しています。 この例ではsizeof(a)とstrlen(a) - 1を引いています。 つまり20 - 10 - 1ということになります。 これで文字配列aに格納する事ができる残りの量を割り出しているわけです。 何故最後に1を引くかですが、これをやらないとstrncpy関数と同様に 最後に'\0'を代入できず、printf関数で出力する際にエラーが起きるためです。 こちらは最後に'\0'を自動で代入するので、strncpyのように最後に自分で入れる必要はないです。 これでちゃんと配列の大きさを超えたらそこは無視するように出来ます。 ただ、これと同じ処理を13行目から書いてはみましたが、正直やっててきつかったですorz 希望があれば解説をしますが、これはstrncat関数の使い方だけ覚えればいいので できれば解説はしない方向でいこうかと思います。 ここで混乱を招くのもどうかと思いますし。 そもそもstrncatと同じ処理の例を紹介した目的は 文字列関数を使用してもらうためですしね^^; 同じ処理さえ出来れば無理して<string.h>を使わなくてもいいだろうと 思われた方を止めるために紹介した例なので分からなくても全く問題ないです。 さて、最後に4つ目としてstrcmp関数を紹介します。 strcmp関数の紹介と例strcmp関数は辞書式に考えてどちらが前にあり、どちらが後にあるか、また同じかを判断してくれる関数です。 これは文字列の並び替えをしたい場合、文字列と別の文字列が等しいかを調べたい時に重宝します。 そういうプログラムは結構作る事が多いのでこの関数は重要です。 それではstrcmp関数の例を示します。 ただ、strcmp関数と同じ処理をするのは難しすぎるので止めさせて頂きます(UU)  どうにか画像を画面内に収めようとしたらこんな詰め詰めの状態になってしまいました。 もちろん皆さんがこれを入力する時はスペースを入れても構いません。むしろ入れた方が見やすいです。 さて、プログラムの解説をしますね。 まず、同じような処理を三回もやることになったので、その部分を関数化するためにプロトタイプを3行目で宣言。 8行目でstrcmp関数を使って、前か後か同じかを判断した結果である戻り値を変数kekkaで受け取ります。 戻り値が負の数ならばaはbより前、正の数ならばaはbより後、同じならaはbと同じ となります。 そして、func関数で前、後、同じでそれぞれの出力を変えるようにしています。 辞書ではabcdeはabcddよりも後にありますね。その通りの出力になります。 後の10~13行目までの処理は全て8,9行目でやっている事と同じです。 このように辞書的に考えてこの文字列はあの文字列とどっちの方が先に出てくるか それぐらい人間には分かりますが、コンピュータにやらせるとなるとかなり面倒な事になります。 その面倒な作業をstrcmp関数を使うだけで済ませられるのですから、これはかなり大きいです。 以上のことから考えても<string.h>の少なくともこの4つの関数は絶対に重要だと思います。 なので、正直数学関数はpow以外覚えなくてもいいぐらいですが、文字列関数はこの4つ覚えて下さい。 まぁ文字列関数には他にも色々ありますが、ここではこの4つでいいですから。 まとめ
さて、例題を考えようとも思ったんですが、今回の章の長さが今まででも最長になってしまったので ここでこの二十四章は終了にします。 次回の二十五章は十四章と同じように例題だけの章にしようと思います。 なので今回は申し訳ありませんが 例題は割愛させて頂きます。 二十五章では簡単なものから難しいものまで例題を揃える予定なので…。 今回の内容も結構難しい内容だったと思いますので頑張って理解して下さいm(_ _)m ここに書いてあることが分からない場合は記事にコメント、もしくはメールをお願いします。 お気に入りの記事を「いいね!」で応援しよう
最終更新日
2007.04.23 12:40:48
コメント(0) | コメントを書く
[C言語] カテゴリの最新記事
|
|






{kind=link}