|
|
|
|
全て
| カテゴリ未分類
| SH4
| AX-12
| シミュレータ
| 夏休み
| あまね
| onPC/sat.
| FPGA
| ロボットビジョン
| SEMB1200A
| 新しい機体
| SH7125
| onPC4th
| 蹴飛ばしても倒れないロボット
| フィールドウォーカー
| 新・新しい機体
| SH7786
| Linux
| Arduino
2020年10月27日
カテゴリ:Linux
実は、週末から次の週末まで、勤続20年のリフレッシュ休暇なんです!
娘の学校があるから、週末に一泊で大阪USJまで旅行には行きましたが、後は自宅警備員(予定)です。 と言う理由で、先々週から取り組んでいる逆動力学部分を仕上げちゃいました!! ちなみに、もちろんNEON化してあるので、91ステップ、23自由度の計算で13ms程度でした。 関節サーボのフィードフォワード用に使うので、1制御周期に1ステップ分計算すれば良いので 本当は計算速度とか、あまり関係ないのだけどね。1ステップ150μsくらいですか。 逆動力学のNEON化は、やはりできるだけ使うレジスタを減らすために、積和演算を多用しています。 計算順序も工夫して、だから、デバックも大変!! コードを印刷してマーカーでチェックして、レジスタの運用もフロー書いて、 シミュレーションの途中の値をとって、エクセル上で一部再現計算して、 1ステップ分の関節トルクも、エクセルで静止時トルク+慣性モーメントも考慮してオーダーチェックして。 ふぅ、疲れた・・・。まあ、大丈夫かな?(^^;;; 「ヒューマノイドロボット改定2版」にオープンソースのロボットシミュレータ「コレオノイド」のことが書かれていた。 C++でコーディングされているらしいから、今度時間があるときに、自分の関節トルクシミュレータと計算結果のチェックをしてみたいな。 時間があったら・・・。 関節トルクまで計算できたから、やっぱり、次は、実機を動かしたいよね。 大量のシミュレーション計算と、サーボ角度指定を同時に「pthread」で処理する。 大丈夫かなー(汗)。まあ、頑張ってみよー!!
あっ、下のグラフは、今回計算した関節トルクを脚部だけ抜粋してグラフ化したものです。 値が大きなものは、ほぼ静止時トルクと同じ値なんですね。 これって、頑張って関節トルクを計算する理由が・・・(涙)。 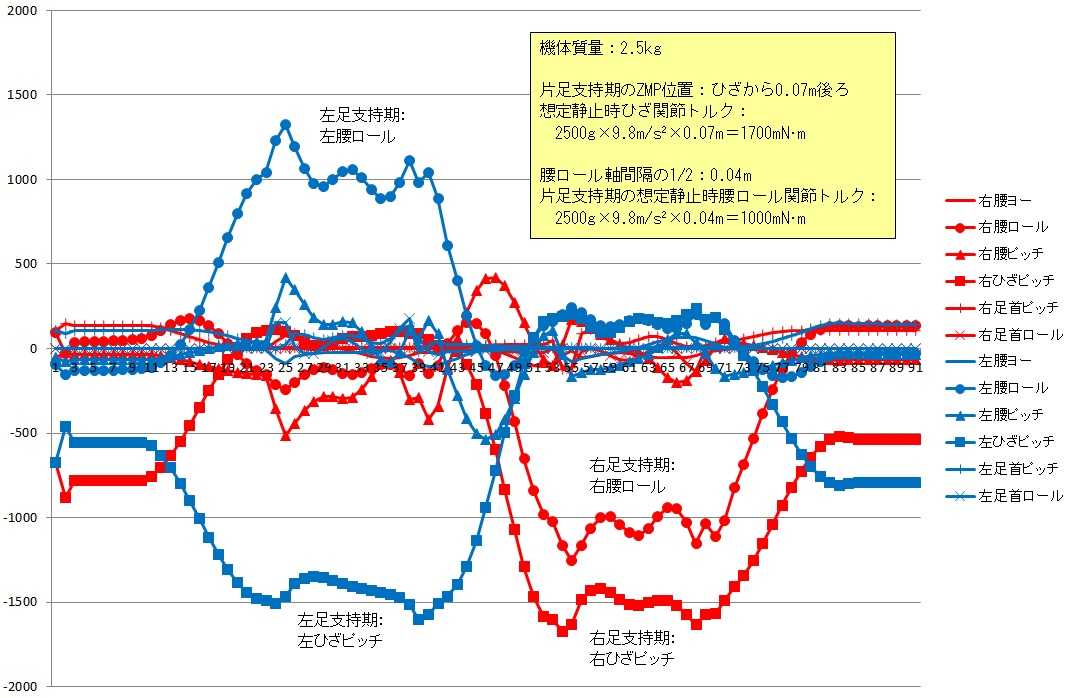 抜粋したコードを以下に示します(逆動力学NEON版)。 足裏反力の計算部分も空間速度で計算しなおしたので、参考にしてください。 /********** 逆動力学 **********/ void ID(LINK lin[],unsigned char j,int s) { unsigned char i; float32x4_t c0,c1,c2,r0,r1,r2,r3; c0 = vdupq_n_f32(0.0); c1 = vdupq_n_f32(0.0); c2 = vdupq_n_f32(0.0); r0 = vld1q_f32( &lin[j].C[0] ); c0 = vsetq_lane_f32( vgetq_lane_f32(r0,2),c0,1); c0 = vsetq_lane_f32(-vgetq_lane_f32(r0,1),c0,2); c1 = vsetq_lane_f32(-vgetq_lane_f32(r0,2),c1,0); c1 = vsetq_lane_f32( vgetq_lane_f32(r0,0),c1,2); c2 = vsetq_lane_f32( vgetq_lane_f32(r0,1),c2,0); c2 = vsetq_lane_f32(-vgetq_lane_f32(r0,0),c2,1); r0 = vmulq_n_f32(c0,vgetq_lane_f32(c0,0)); r0 = vmlaq_n_f32(r0,c1,vgetq_lane_f32(c1,0)); r0 = vmlaq_n_f32(r0,c2,vgetq_lane_f32(c2,0)); r1 = vmulq_n_f32(c0,vgetq_lane_f32(c0,1)); r1 = vmlaq_n_f32(r1,c1,vgetq_lane_f32(c1,1)); r1 = vmlaq_n_f32(r1,c2,vgetq_lane_f32(c2,1)); r2 = vmulq_n_f32(c0,vgetq_lane_f32(c0,2)); r2 = vmlaq_n_f32(r2,c1,vgetq_lane_f32(c1,2)); r2 = vmlaq_n_f32(r2,c2,vgetq_lane_f32(c2,2)); c0 = vmulq_n_f32(r0,lin[j].m); c1 = vmulq_n_f32(r1,lin[j].m); c2 = vmulq_n_f32(r2,lin[j].m); r2 = vmulq_n_f32(c0,lin[j].w[0]); // I*w r2 = vmlaq_n_f32(r2,c1,lin[j].w[1]); r2 = vmlaq_n_f32(r2,c2,lin[j].w[2]); r3 = vmulq_n_f32(c0,lin[j].dw[0]); // I*dw r3 = vmlaq_n_f32(r3,c1,lin[j].dw[1]); r3 = vmlaq_n_f32(r3,c2,lin[j].dw[2]); c0 = vdupq_n_f32(0.0); c1 = vdupq_n_f32(0.0); c2 = vdupq_n_f32(0.0); r0 = vld1q_f32( &lin[j].C[0] ); c0 = vsetq_lane_f32( vgetq_lane_f32(r0,2),c0,1); c0 = vsetq_lane_f32(-vgetq_lane_f32(r0,1),c0,2); c1 = vsetq_lane_f32(-vgetq_lane_f32(r0,2),c1,0); c1 = vsetq_lane_f32( vgetq_lane_f32(r0,0),c1,2); c2 = vsetq_lane_f32( vgetq_lane_f32(r0,1),c2,0); c2 = vsetq_lane_f32(-vgetq_lane_f32(r0,0),c2,1); r0 = vmulq_n_f32(c0,lin[j].v0[0]); r0 = vmlaq_n_f32(r0,c1,lin[j].v0[1]); r0 = vmlaq_n_f32(r0,c2,lin[j].v0[2]); r0 = vmulq_n_f32(r0,lin[j].m); r2 = vaddq_f32(r0,r2); // L r0 = vmulq_n_f32(c0,lin[j].dv0[0]); r0 = vmlaq_n_f32(r0,c1,lin[j].dv0[1]); r0 = vmlaq_n_f32(r0,c2,lin[j].dv0[2]); r0 = vmulq_n_f32(r0,lin[j].m); r3 = vaddq_f32(r0,r3); // r0 = vld1q_f32( &lin[j].w[0] ); c0 = vsetq_lane_f32( vgetq_lane_f32(r0,2),c0,1); c0 = vsetq_lane_f32(-vgetq_lane_f32(r0,1),c0,2); c1 = vsetq_lane_f32(-vgetq_lane_f32(r0,2),c1,0); c1 = vsetq_lane_f32( vgetq_lane_f32(r0,0),c1,2); c2 = vsetq_lane_f32( vgetq_lane_f32(r0,1),c2,0); c2 = vsetq_lane_f32(-vgetq_lane_f32(r0,0),c2,1); r0 = vld1q_f32( &lin[j].v0[0] ); r0 = vmlaq_n_f32(r0,c0,lin[j].C[0]); r0 = vmlaq_n_f32(r0,c1,lin[j].C[1]); r0 = vmlaq_n_f32(r0,c2,lin[j].C[2]); r1 = vmulq_n_f32(r0,lin[j].m); // P r0 = vmlaq_n_f32(r3,c0,vgetq_lane_f32(r2,0)); r0 = vmlaq_n_f32(r0,c1,vgetq_lane_f32(r2,1)); r3 = vmlaq_n_f32(r0,c2,vgetq_lane_f32(r2,2)); // r2 = vmulq_n_f32(c0,vgetq_lane_f32(r1,0)); r2 = vmlaq_n_f32(r2,c1,vgetq_lane_f32(r1,1)); r2 = vmlaq_n_f32(r2,c2,vgetq_lane_f32(r1,2)); // r0 = vld1q_f32( &lin[j].dw[0] ); c0 = vsetq_lane_f32( vgetq_lane_f32(r0,2),c0,1); c0 = vsetq_lane_f32(-vgetq_lane_f32(r0,1),c0,2); c1 = vsetq_lane_f32(-vgetq_lane_f32(r0,2),c1,0); c1 = vsetq_lane_f32( vgetq_lane_f32(r0,0),c1,2); c2 = vsetq_lane_f32( vgetq_lane_f32(r0,1),c2,0); c2 = vsetq_lane_f32(-vgetq_lane_f32(r0,0),c2,1); r0 = vld1q_f32( &lin[j].dv0[0] ); r0 = vmlaq_n_f32(r0,c0,lin[j].C[0]); r0 = vmlaq_n_f32(r0,c1,lin[j].C[1]); r0 = vmlaq_n_f32(r0,c2,lin[j].C[2]); r0 = vmulq_n_f32(r0,lin[j].m); r2 = vaddq_f32(r0,r2); // f0 r0 = vld1q_f32( &lin[j].v0[0] ); c0 = vsetq_lane_f32( vgetq_lane_f32(r0,2),c0,1); c0 = vsetq_lane_f32(-vgetq_lane_f32(r0,1),c0,2); c1 = vsetq_lane_f32(-vgetq_lane_f32(r0,2),c1,0); c1 = vsetq_lane_f32( vgetq_lane_f32(r0,0),c1,2); c2 = vsetq_lane_f32( vgetq_lane_f32(r0,1),c2,0); c2 = vsetq_lane_f32(-vgetq_lane_f32(r0,0),c2,1); r0 = vmlaq_n_f32(r3,c0,vgetq_lane_f32(r1,0)); r0 = vmlaq_n_f32(r0,c1,vgetq_lane_f32(r1,1)); r3 = vmlaq_n_f32(r0,c2,vgetq_lane_f32(r1,2)); // t0 // if ( (s == 25) && (j == 5) ){ // printf("t0 %12.6e %12.6e %12.6e\n",vgetq_lane_f32(r3,0),vgetq_lane_f32(r3,1),vgetq_lane_f32(r3,2)); // } r1 = vdupq_n_f32(0.0); r1 = vsetq_lane_f32(-lin[j].m*g,r1,2); r2 = vsubq_f32( r2, r1 ); r0 = vld1q_f32( &lin[j].C[0] ); c2 = vsetq_lane_f32( vgetq_lane_f32(r0,1),c2,0); c2 = vsetq_lane_f32(-vgetq_lane_f32(r0,0),c2,1); r0 = vmulq_n_f32(c2,vgetq_lane_f32(r1,2)); r3 = vsubq_f32( r3, r0 ); i = lin[j].child; if ( i == 0 ) { if ( j == 7 ) { r0 = vld1q_f32( &lin[j].fEp[0] ); r1 = vld1q_f32( &lin[j].fE[0] ); r2 = vsubq_f32( r2, r1 ); c0 = vsetq_lane_f32( vgetq_lane_f32(r0,2),c0,1); c0 = vsetq_lane_f32(-vgetq_lane_f32(r0,1),c0,2); c1 = vsetq_lane_f32(-vgetq_lane_f32(r0,2),c1,0); c1 = vsetq_lane_f32( vgetq_lane_f32(r0,0),c1,2); c2 = vsetq_lane_f32( vgetq_lane_f32(r0,1),c2,0); c2 = vsetq_lane_f32(-vgetq_lane_f32(r0,0),c2,1); r0 = vmulq_n_f32(c0,vgetq_lane_f32(r1,0)); r0 = vmlaq_n_f32(r0,c1,vgetq_lane_f32(r1,1)); r0 = vmlaq_n_f32(r0,c2,vgetq_lane_f32(r1,2)); r3 = vsubq_f32( r3, r0 ); } else if ( j == 13 ) { r0 = vld1q_f32( &lin[j].fEp[0] ); r1 = vld1q_f32( &lin[j].fE[0] ); r2 = vsubq_f32( r2, r1 ); c0 = vsetq_lane_f32( vgetq_lane_f32(r0,2),c0,1); c0 = vsetq_lane_f32(-vgetq_lane_f32(r0,1),c0,2); c1 = vsetq_lane_f32(-vgetq_lane_f32(r0,2),c1,0); c1 = vsetq_lane_f32( vgetq_lane_f32(r0,0),c1,2); c2 = vsetq_lane_f32( vgetq_lane_f32(r0,1),c2,0); c2 = vsetq_lane_f32(-vgetq_lane_f32(r0,0),c2,1); r0 = vmulq_n_f32(c0,vgetq_lane_f32(r1,0)); r0 = vmlaq_n_f32(r0,c1,vgetq_lane_f32(r1,1)); r0 = vmlaq_n_f32(r0,c2,vgetq_lane_f32(r1,2)); r3 = vsubq_f32( r3, r0 ); } } else { ID(lin,i,s); r0 = vld1q_f32( &lin[i].f[0] ); r1 = vld1q_f32( &lin[i].t[0] ); r2 = vaddq_f32(r0,r2); r3 = vaddq_f32(r1,r3); } if ( j == 1 ) { } else { r0 = vld1q_f32( &lin[j].sv[0] ); r1 = vld1q_f32( &lin[j].sw[0] ); r0 = vmulq_f32(r0,r2); r1 = vmulq_f32(r1,r3); r0 = vaddq_f32(r0,r1); lin[j].u = vgetq_lane_f32(r0,0) + vgetq_lane_f32(r0,1) + vgetq_lane_f32(r0,2); } i = lin[j].sister; if ( i == 0 ) { } else { ID(lin,i,s); r0 = vld1q_f32( &lin[i].f[0] ); r1 = vld1q_f32( &lin[i].t[0] ); r2 = vaddq_f32(r0,r2); r3 = vaddq_f32(r1,r3); } vst1q_f32( &lin[j].f[0], r2 ); // f vst1q_f32( &lin[j].t[0], r3 ); // t } /********** 足裏反力の算定 **********/ LR = 0.0; sR = 0.0; Lzmp = 0.0; szmp = 0.0; ezmp = 0.0; LRzmp = 0.0; if ( step[s].lfoot_s == 1 ) { if ( step[s].rfoot_s == 1 ) { // 両足支持 LR = sqrtf((step[s].rfoot_x - step[s].lfoot_x)*(step[s].rfoot_x - step[s].lfoot_x) + (step[s].rfoot_y - step[s].lfoot_y)*(step[s].rfoot_y - step[s].lfoot_y)); sR = atan2f(step[s].rfoot_y - step[s].lfoot_y, step[s].rfoot_x - step[s].lfoot_x); Lzmp = sqrtf((zmp[s].x - step[s].lfoot_x)*(zmp[s].x - step[s].lfoot_x) + (zmp[s].y - step[s].lfoot_y)*(zmp[s].y - step[s].lfoot_y)); szmp = atan2f(zmp[s].y - step[s].lfoot_y, zmp[s].x - step[s].lfoot_x); ezmp = Lzmp * sinf( szmp - sR ); LRzmp = Lzmp * cosf( szmp - sR ); if ( LRzmp < 0.0 ) { // 左足支持 lF[0] = Fx; lF[1] = Fy; lF[2] = Fz; lF[3] = 0.0; rF[0] = 0.0; rF[1] = 0.0; rF[2] = 0.0; rF[3] = 0.0; lFp[0] = zmp[s].x; lFp[1] = zmp[s].y; lFp[2] = 0.0; lFp[3] = 0.0; rFp[0] = 0.0; rFp[1] = 0.0; rFp[2] = 0.0; rFp[3] = 0.0; } else if ( LRzmp > LR ) { // 右足支持 lF[0] = 0.0; lF[1] = 0.0; lF[2] = 0.0; lF[3] = 0.0; rF[0] = Fx; rF[1] = Fy; rF[2] = Fz; rF[3] = 0.0; lFp[0] = 0.0; lFp[1] = 0.0; lFp[2] = 0.0; lFp[3] = 0.0; rFp[0] = zmp[s].x; rFp[1] = zmp[s].y; rFp[2] = 0.0; rFp[3] = 0.0; } else { // 両足支持 lF[0] = Fx / LR * (LR - LRzmp); lF[1] = Fy / LR * (LR - LRzmp); lF[2] = Fz / LR * (LR - LRzmp); rF[0] = Fx / LR * LRzmp; rF[1] = Fy / LR * LRzmp; rF[2] = Fz / LR * LRzmp; ex = ezmp * cosf( sR + PI/2 ); ey = ezmp * sinf( sR + PI/2 ); lFp[0] = step[s].lfoot_x + ex; lFp[1] = step[s].lfoot_y + ey; lFp[2] = 0.0; lFp[3] = 0.0; rFp[0] = step[s].rfoot_x + ex; rFp[1] = step[s].rfoot_y + ey; rFp[2] = 0.0; rFp[3] = 0.0; } } else { // 左足支持 lF[0] = Fx; lF[1] = Fy; lF[2] = Fz; lF[3] = 0.0; rF[0] = 0.0; rF[1] = 0.0; rF[2] = 0.0; rF[3] = 0.0; lFp[0] = zmp[s].x; lFp[1] = zmp[s].y; lFp[2] = 0.0; lFp[3] = 0.0; rFp[0] = 0.0; rFp[1] = 0.0; rFp[2] = 0.0; rFp[3] = 0.0; } } else { // 右足支持 lF[0] = 0.0; lF[1] = 0.0; lF[2] = 0.0; lF[3] = 0.0; rF[0] = Fx; rF[1] = Fy; rF[2] = Fz; rF[3] = 0.0; lFp[0] = 0.0; lFp[1] = 0.0; lFp[2] = 0.0; lFp[3] = 0.0; rFp[0] = zmp[s].x; rFp[1] = zmp[s].y; rFp[2] = 0.0; rFp[3] = 0.0; } link[7].fE[0] = rF[0]; link[7].fE[1] = rF[1]; link[7].fE[2] = rF[2]; link[7].fE[3] = 0.0; link[7].fEp[0] = rFp[0]; link[7].fEp[1] = rFp[1]; link[7].fEp[2] = rFp[2]; link[7].fEp[3] = 0.0; link[13].fE[0] = lF[0]; link[13].fE[1] = lF[1]; link[13].fE[2] = lF[2]; link[13].fE[3] = 0.0; link[13].fEp[0] = lFp[0]; link[13].fEp[1] = lFp[1]; link[13].fEp[2] = lFp[2]; link[13].fEp[3] = 0.0; ID(link,1,s); お気に入りの記事を「いいね!」で応援しよう
最終更新日
2020年10月27日 10時13分42秒
[Linux] カテゴリの最新記事
|
|
|