|
|
|
|
2016年12月19日
カテゴリ:Advent Calendar
この記事は、Rakuten Advent Calendar 2016 の19日目の記事です。
こんにちは、楽天トラベルでDevOpsを担当しているShinoです。 DevOpsと一口に言っても色々ありますが、端的に言うとオペレーション・ゼロを目指して、運用やCI/CD周りの自動化、プラットフォーム開発に励んでいます。
2日目のkawaguti氏の記事「(12月2日) DevOps とリーンスタートアップ時代のプロダクトオーナーシップ」にもありましたが、メトリクスの共有 は、重要なアジャイルプラクティスの1つだと言われています。 スクラムやリーンをやっているチームは何かしらの指標を持ってると思いますが、メトリクスはチームによって多種多様で、多くのセオリーやアンチパターンなどがあります。その中で、ウォーターロイス氏がこちらの記事で提言している、
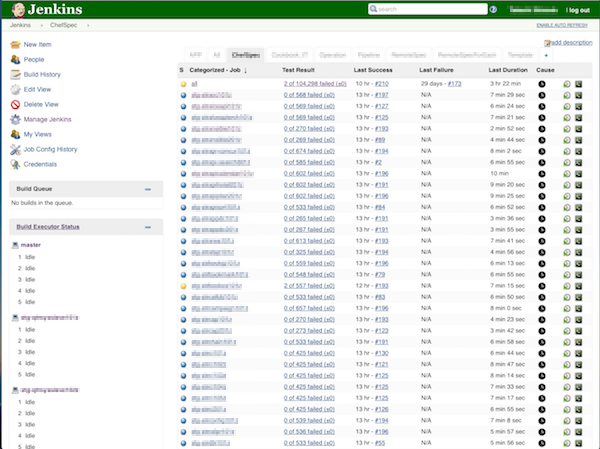
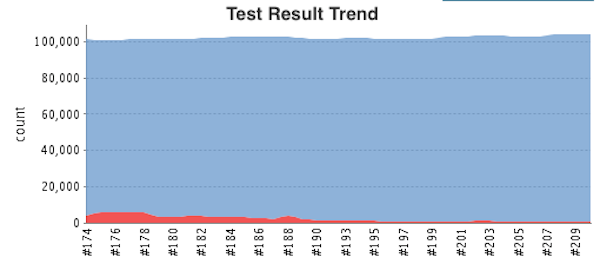
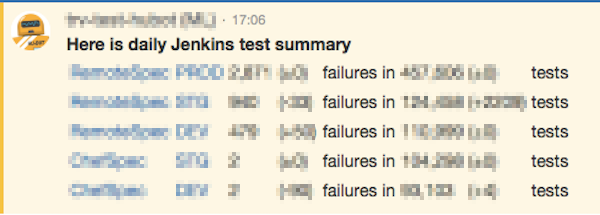
の2つについて私達の事例を紹介します。 品質のメトリクス 私達の部署の役割の一つとして、サーバ構築やOS、ミドルウェア設定などのオペレーションがあります。 所謂アプリケーションのUTやITとは異なりますが、私たちにとっては、コードの品質および実サーバの状態を確認する上で大切な指標です。 Chefのコードのテストのためにはテスト用のVMが必要になりますが、(一般的にも)これらは稼働数や時間に応じて課金されてしまうので、開発環境、ステージング環境では、仮想VM(仮想の仮想、、)としてDockerを使い、MinimalOSおよび中間のDisk imageから、Chefでプロビジョニングして、Serverspecで設定反映後のテストをするということをやっています。また、本番環境を含め実際稼働しているサーバの状態をチェックするために、同じServespecのテストケースを用いて、1日数回結果をレポートしています。
計測し始めた当時は同じクックブックのテストでも、このサーバでは通るけどこのサーバでは上手くいかないなど、もぐらたたきでした。割れ窓理論でなかなか修正が進まなかった現実も、、 現在は、本番環境では、約45万、DEV/STGではそれぞれおよそ10万件くらいのテストが走り、テストがこけてもすぐに気づいて対応できる体制になりました。
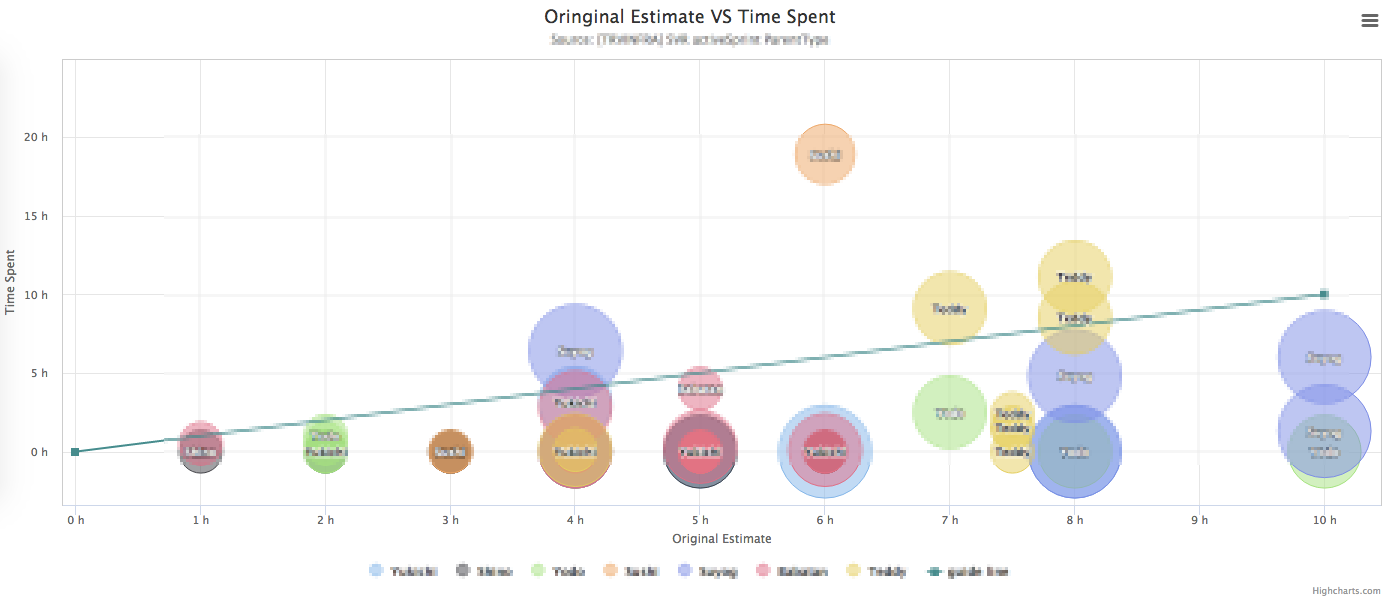
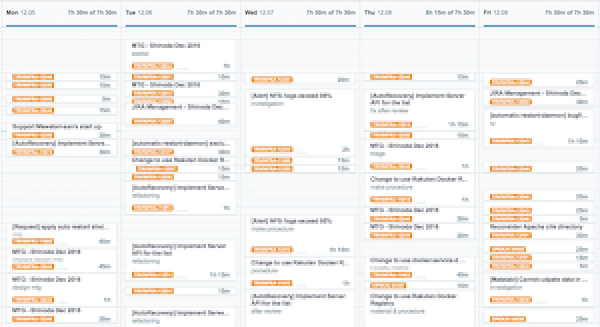
楽天グループでは、開発プロジェクトの進捗管理にAtlassian社のJIRAというツールを使っています。 このツールは非常に強力で、KANBANを用いてタスク管理をしたり、WEB上で承認ワークフローを回したり、バーンダウンチャートで進捗を確認したりと、アジャイル開発をする上で必要になる機能が詰まっています。ただ、個人的にはレポーティングは少し痒いところに手が届かなかったりするので、JIRA Restful APIやHTMLパースによって追加で情報を取得し加工しています。 メトリクスは少ない方がいいというセオリーは全くその通りだと思いますし、強いチームなら、デイリーハドル、KANBAN、バーンダウンチャートくらいがあれば事足りるでしょう。実際に下記に推奨されるメトリクスを用いていましたが、私達のチームではそれだけでは上手く行きませんでした。 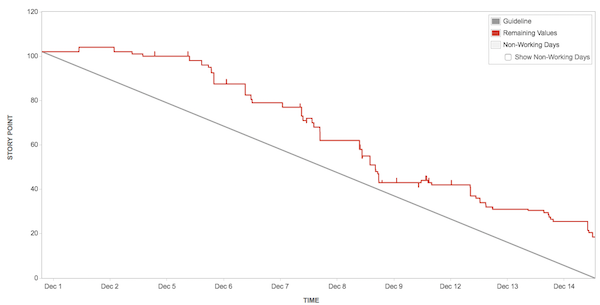 理想ラインに漸近するも交わらない バーンダウンが落ちない。まさにウォーターフォールのごとく後半に急激に落ちる。似たようなことは別のチームにいた際もよく起きていましたがまたしても。。 これらはストーリーポイントやIssueの数をベースにした指標ですが、そもそもIssueをクローズできなかったり想定より時間がかかっていました。チケットの分割し、タスクを細分化していきましたが、そうすると数値を管理するのが難しくなります。 時間見積もりや評価は、時にアンチパターンとされることもありますが、何にどれくらい時間を使っているかをまず見える化し、改善する方が自分たちのスタイルにあっていると考え、いくつかメトリクスを追加、視覚化して改善を図ってきました。 そのベースになるのが、チケットごとにどれくらい時間を使ったかを記録するWorklogです。
細々とした物含め、全ての仕事に対して、ログをつけるのはストレスになることもありますが、ルールをきちんと決め習慣化することでストレスを軽減し、結果的にチケットドリブンになるという効果もありました。 上記は個人の例ですが、チームとしてサマるとこんな感じになります。
最初はWeelyで評価していましたが、2週間のスプリントにおいて1週間単位ではちょっとフィードバックとしては遅すぎます。そこで、Dailyかつ個人ベースで取得するようにしました。
これらを細かく分析するのではなく、コミュニケーションのきっかけくらいの役割ですが、これにより早く問題に気づき、また上手くいっているところも分かりやすくなったので、タスクの再アサインや他のメンバーのサポートがしやすくなりました。それぞれの見積もりや進め方の癖みたいなのも筒抜けですw まとめ 上記は、厳密にはロイス氏の言う進捗や品質とは違いますし、メトリクスというのはあくまで指標であり、成果ではありません。 これらを日毎、週毎、2週間のSprint毎に確認し、傾向を掴み対策を行っていますが、チームの成果としては、上記とは別にKGI(Key Goal Indicator)を定義して月毎に評価をしています。 当然サービス品質や可用性を担保した上で、実際にオペレーションの数が減っているか、サーバ構築のリードタイムが減っているか などがそれに当たります。 私達が各種メトリクスを採用する上で大切なことは、まず「チームの変化に気づけること」。良いことは褒めあい高め合う、悪いことはサポートしあい早く改善する。また、それらが、「チームに合っているか」。これは重要な原則の一つですが、チーム全員が納得できるか、また有効であるかどうかを常に議論し改善する必要があります。私たちも今のスタイルに落ち着くまで1年くらいかかりましたし、更に新しいものを追加しようと考えている自分もいますw それと、このメトリクスは今使っているツールでは取れないから計測しない。ではなく、有用だと思う指標があれば、取得方法を考えて計測してみる。というのが大事ですね!視覚化ももちろん大事です。 再三同じことを言ってますが、メトリクスの使い方は十人十色だと思います。うちではこうだけど、そっちはそうなのかーと参考になれば幸いです。 長くなりましたが、メトリクスおじさんからは以上です。 お気に入りの記事を「いいね!」で応援しよう
Last updated
2016年12月19日 09時13分05秒
コメント(0) | コメントを書く
[Advent Calendar] カテゴリの最新記事
|
|



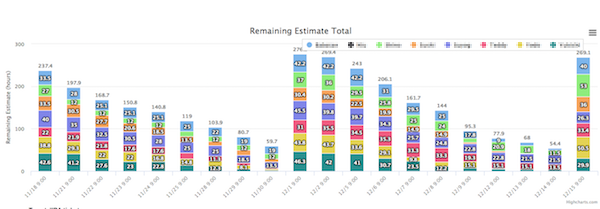 チーム全体の残見積もり時間(縦軸が時間、横軸が日付)
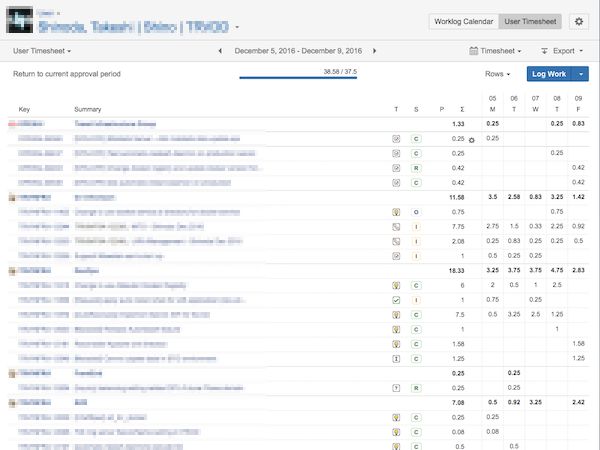
チーム全体の残見積もり時間(縦軸が時間、横軸が日付)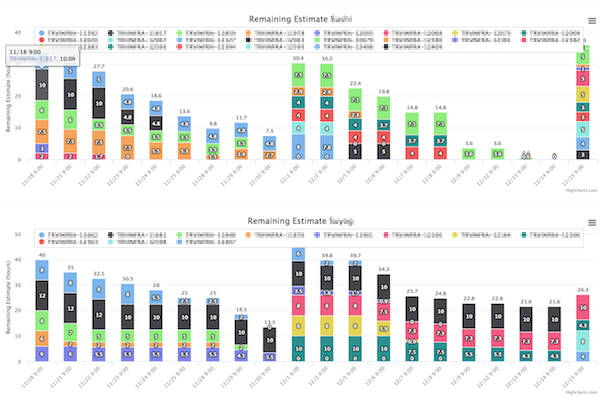 個人別のものはタスクごとにわかれています(縦軸が時間、横軸が日付)
個人別のものはタスクごとにわかれています(縦軸が時間、横軸が日付)