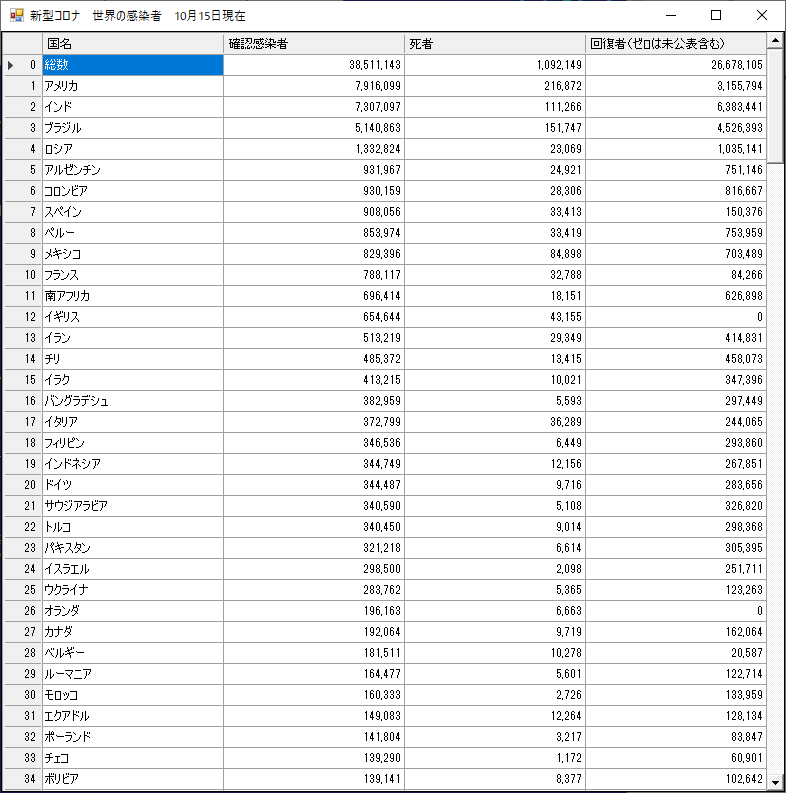
XMLでなんちゃってDB
仮掲示板での質問「配列を組み合わせて集計したい」。さすがstuncloudさんがさくっと回答しておられました。質問は件数を数えるだけだったので、複数の属性をそのまま文字列としてくっつけ連想配列で処理するというものでした。とはいえ、複数の属性にまたがったしぼ売込み絞り込み条件で検索・列挙・集計したいとなると単純な配列や連想配列では荷が重すぎます。こういうのは普通、データベースを構築してSQL文でクエリーを行うのでしょうけど、DBの構築だけでも結構な作業。UWSC一本でシンプルにできないかと考え、XMLの要素を探索するxpath式でクエリーを発行することを考えました。お題は質問と同じ果物でやってみました。どうせなら本格的なものを、と、農水省謹製のCSVを(ここらへんからリンクをたどって)拾って解析しています。なんちゃってDB.uws//青果市況をXMLに読み込みSQL文//IEがいると邪魔なので殺すpowershell("ps iexplore|kill")//XMLの準備xml=createoleobj( "Msxml2.DOMDocument.6.0" )xml.loadxml("<?xml version='1.0' encoding='utf-16'?><fruits/>")rootnode=xml.selectSingleNode("//fruits")//msgbox(xml.xml)//WebからCSVを落としてきて、XMLに読み込むCsvString=getFruitsMarketData()CsvTexts=split(CsvString,"<#CR>")sendstr(0,CsvTexts[0])titles=split(CsvTexts[0],",")for i=1 to length(CsvTexts)-1 terms=split(CsvTexts[i], ",") node=xml.createElement( "fruit"+i ) for j=0 to length( titles )-1 subnode=xml.createElement( titles[j] ) subnode.text=terms[j] node.appendChild(subnode) next rootnode.appendChild(node)next//べつにセーブする必要はないけれど書き出しておくほうが便利saveXmlWithIndent( xml, "C:\Users\satocha\Desktop\fruits.xml" )////////////////ここからDB(実はただのXML)へのクエリーをやってみる//温州みかんの産地を調べるfukidasi("温州みかんの産地を調べる")hashtbl ProducingAreafor node in getoleitem(xml.selectNodes("//品目名[contains(text(),'温州')]")) area=node.parentNode.selectSingleNode("産地名").text if area <> "" ProducingArea[ area ]="dmy" endifnextfor i=0 to length(ProducingArea)-1 msgbox( ProducingArea[i,hash_key] )next//愛媛産の果物をリストアップするfukidasi("愛媛産の果物をリストアップする")hashtbl FruitsOfEhimefor node in getoleitem(xml.selectNodes("//産地名[text()='愛 媛']")) fruit=node.parentNode.selectSingleNode("品目名").text if area <> "" FruitsOfEhime[ fruit ]="dmy" endifnextfor i=0 to length(FruitsOfEhime)-1 msgbox( FruitsOfEhime[i,hash_key] )next//////////////////////////////関数定義//セーブ用関数 いらないんだけどどうせならきれいにインデントしてセーブfunction saveXmlWithIndent( xml, path ) writer =createoleobj( "MSXML2.MXXMLWriter" ) reader =createoleobj("MSXML2.SAXXMLReader") fso =createoleobj("Scripting.FileSystemObject") textStream = fso.CreateTextFile( path, 1, -1 ) writer.indent = true writer.omitXMLDeclaration = true reader.contentHandler = writer reader.parse( xml ) textStream.Write(writer.output) textStream.Close() result=fopen( path, f_exists )fend//農水省の青果市況情報をCSVに落とす関数。//今回の主眼はスクレイピングじゃないのでやっつけ仕事。//IEの設定によっては手直しが必要function getFruitsMarketData( market="豊洲" ) BaseUrl="https://www.seisen.maff.go.jp/seisen/bs04b040md001/BS04B040UC010SC999-Evt001.do" Ie=CreateOleObj( "InternetExplorer.Application" ) Ie.Navigate( BaseUrl ) repeat fukidasi("waiting") try if !Pos( "青果物市況情報画面", Ie.document.title ) continue endif except continue endtry fukidasi("") break until false DateStr="" hashtbl ATagList for ATag in getoleitem( Ie.Document.GetElementsByTagName("A") ) text=trim(ATag.innerText) if Copy( text, 5, 1 )<>"年" then continue DateStr=DateStr+" "+text ATagList[ text ]=ATag.href next DateArray=split( trim(DateStr), " " ) qsort(DateArray,QSRT_NATURALD) Newest=DateArray[0] Ie.Navigate( ATagList[Newest] ) repeat fukidasi("waiting") try if !Pos( "東京都中央卸売市場豊洲市場", Ie.document.body.innerText ) continue endif except continue endtry fukidasi("") break until false hashtbl TdTagList for TdTag in getoleitem( Ie.Document.GetElementsByTagName("TD") ) text=trim(TdTag.innerText) if Pos( market, text ) if !pos( "<td>", TdTag.innerHTML ) break endif endif TdTag=null next if TdTag<>null getOleItem( TdTag.NextSibling.NextSibling.NextSibling.NextSibling.GetElementsByTagName("A") ) Ie.Visible=true all_ole_item[1].click() clkitem( getid( Ie.Document.title ) ,"保存",CLK_ACC) Ie.Visible=false else msgbox( "市場:" + market + "が見つかりません" ) exit endif Ie.Quit() //ダウンロードフォルダに落ちてくると決め打ち。ダウンロード失敗も考慮していない。 DLFolder=replace(Get_Appdata_Dir,"Appdata\roaming","Downloads" ) n=GetDir( DLFolder, "*.csv", true, 2 ) if n > 0 csv=DLFolder + "\" + getdir_files[n-1] fd=fopen( csv, f_read ) result=fget(fd,f_alltext) fclose(fd) deletefile( csv ) endiffend