|
|
|
|
2019.08.19
▼楽天市場の特定の商品のレビューを「R言語」でスクレイピングするコード:一部の項目の空欄・欠損値(missing values)を「NA」に置き換えてデータフレームを作成:継ぎはぎのコードですが・・・
カテゴリ:データ分析
楽天市場の特定の商品のレビューをスクレイピングして、テキストマイニングをしようとすると、「性・年代」「レビューの見出し」など、いろいろな項目で空欄(欠損値)がかなり多く見られます。
「日付」「☆の数」「レビュー本文」など、欠損値のない項目をスクレイピングして、データフレームを作成するのは、ネット上に紹介されているコードを利用すれば簡単にできました。 しかし、「名前」や「レビューの見出し」など、欠損値(missing values)がある項目を含めてスクレイピングしようとすると、列ごとの行数が合わなくなったりするため、「欠損値なし」の項目でうまくいった方法ではエラーになり、データフレームを作成することができませんでした。欠損値は、たった一つであってもエラーになってしまいます。 プログラミングに不案内な私は、ネット上でいろいろと調べ、紹介されているコードをコピペして、継ぎはぎですが、下記のような「R」のコードができました。下図のように、一部の項目の欠損値は「NA」として取り込めています。 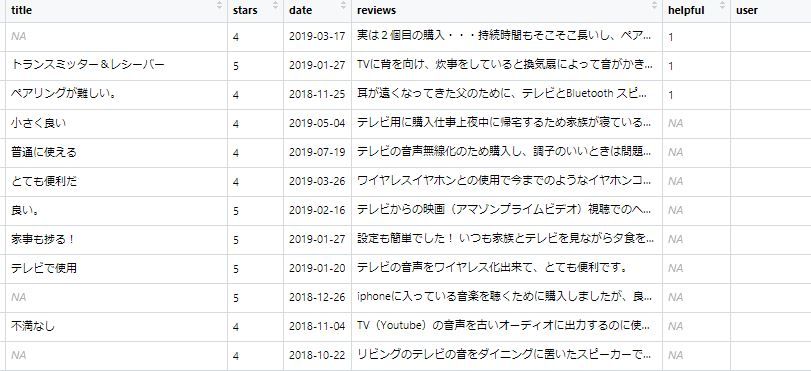 Webスクレイピングでは、欠損値の存在が前提だと思うのですが、意外と「欠損値」のあるデータをスクレイピングする場合のコードが紹介されていません。 ネット上で紹介されているコードは、欠損値のない項目だけを対象にしているものが多かったりします。 以下の継ぎはぎのコードでは、「名前」「見出し」などの欠損値に「NA」を充当し、なんとかデータフレームが作成できるようになりました。 もちろん、「名前」はなくてもいいのですが、行ずれなどが簡単に確認できるので、あった方が便利だと思います。 現状のコードで取得したデータでは、「投稿者の性・年代」「商品の使いみち」「商品を使う人」「購入した回数」といった項目については、Excelシート上で「列の分割」を行って、切り分ける必要があります。 Excelシートでの切り分け処理も実用上はそれほど支障はありませんが、コード上でもっと細かい切り分けができるようになればいいと思っています。 どなたか、エレガントなRのコードを公開していただけないでしょうか。コードの勉強をさせていただきます。 ▼Rのコード(継ぎはぎ試作版)→このコードには改訂版があります ------------------------------------------------------------------------------ url_txt <- "https://review.rakuten.co.jp/item/1/・・・/" #特定の商品のレビュー一覧ページのURLの末尾を一部(4文字分)除いたものを記入※。 pages_num <- 10 #レビュー一覧の最後のページのページ数を確認して記入。例は「10ページ」の場合。 get_r_reviews <- NULL df_reviews <- NULL for(i in 1:pages_num) { url <- paste0(url_txt,i,'.','1/') page <- read_html(url) get_r_reviews <- page %>% html_nodes ('.hreview') %>% map_df(~list( name = html_nodes(.x, '.reviewer') %>% html_text(.,trim = FALSE) %>% {if(length(.) == 0) NA else .}, title = html_nodes(.x, '.summary') %>% html_text(.,trim = FALSE) %>% {if(length(.) == 0) NA else .}, stars = html_nodes(.x, '.value') %>% html_text() , date = html_nodes(.x, '.dtreviewed') %>% html_text() , reviews = html_nodes(.x, '.description') %>% html_text(.,trim = FALSE) , helpful = html_nodes(.x, '.revEntryAnsNum') %>% html_text(.,trim = FALSE) %>% {if(length(.) == 0) NA else .} , user = html_nodes(.x, '.revUserFaceDtlUnder') %>% html_text(.,trim = FALSE) %>% {if(length(.) == 0) NA else .}, usage = html_nodes(.x, '.revRvwUserDisp') %>% html_text(.,trim = FALSE) )) Sys.sleep(5)df_reviews <- rbind(df_reviews, get_r_reviews) } view(df_reviews) ------------------------------------------------------------------------------ ※留意事項:1行目の「url_txt」の右の” ”のところに、楽天市場の特定の商品の「みんなのレビュー」の一覧ページのURLを記入するのですが、末尾の「1.1/」や「2.1/」よりも前の部分のURLの「・・・/」までを記入します。「.」や「/」が過不足しないように注意する必要があります。 「for i」文の「i」がURLの末尾の「i.1/」のところに入る形です。この「i」の後ろに「.」と「1」と「/」を付け足しています。URLの末尾が「1.1/」「2.1/」「3.1/」「4.1/」「5.1/」と変化することで、無理やり、ページ送りをしています。 ※2行目の「pages_num <- 10」のところですが、数字の「10」のところにレビューのページの最終ページの数字を調べて記入します。5ページ目が最終ページであれば「5」を記入して「pages_num <- 5」とします。 なお、公開されているページの上限は「100」のようです。20,000件を超えるレビューがある商品でも100ページまでしか表示されませんでした。 ※必要なパッケージ 私の環境ですが、Rstudioを利用しています。上記コードに必要なパッケージは、おそらく下記のようなものではないでしょうか。いろいろと試行錯誤したので、上記コードには不要なパッケージもいくつか含まれているはずです(笑)。なお、Rstudioに未登録のパッケージは、「install.packages()」などによって、インストールしておく必要があります。 library(rvest) library(purrr) library(pipeR) library(textreadr) library(RCurl) library(XML) library(tidyverse) library(lubridate) 楽天市場のレビューは、欠損値(入力がない項目)が多くあるので、どちらかというとスクレイピングがしにくくなっていると思います。欠損値のない項目だけにすればいいのでしょうが、レビューの「見出し」くらいはほしいと思いました。 「性・年代」の部分は、より広範囲の部分を取り込んでいるので、Excelの列の分割で、区切り位置を「スペース」にして分割して、切り分けます。その際、切り分ける「user」の列の右側に空の列を8列挿入しておきます。そうしないと、隣の「others」の列が上書きされてしまいます。 また、「商品の使いみち」「商品を使う人」「購入した回数」の3項目の属性が同じなので、コード処理が面倒でした。というか、方法がよくわかりませんでした。 【20190824:コード中の「others」を「usage」にして取得範囲を変更しました】 【「商品の使いみち」「商品を使う人」「購入した回数」の3項目を含む範囲を「usage」として一括して取り込んでいます。今後の課題です。 Excelの列の分割で、区切り位置を「スペース」で分割すると3項目を簡単に切り分けることができます。ただし、3項目がそろっていないレビューの行では列がずれているので、フィルターで行を並べ替えながら、ずれた部分を整える必要があります。】 なお、例えば「見出し」のセルの中の「NA」の文字列が不要の場合は、Excel上で「置き換え」処理によって削除します。特に、ワードクラウドなどに使う場合は、必ず削除しておきます。削除が前提であれば、「’NA_99’」とか、普通の文字列に出てこないような文字列にしておくのがいいかもしれません。 レビューデータが入手できれば、あとはユーザーローカルさんのテキストマイニングツールやMicrosoft Power BIなどに取り込んで簡単に分析することができます。 結論としては、楽天市場のみんなのレビューのページで、ユーザーローカルのテキストマイニング結果のような分析情報(特に、「見出しクラウド」のような情報)が見られれば、スクレイピングのような面倒なことは不要になって、ユーザーも楽天もハッピーなのではないかと思います。 それができないのであれば、もっとスクレイピングしやすい形にしてほしいと思います。アマゾンの方が、スクレイピングしやすいということになれば、アマゾンの方が話題になりやすくなるので、楽天にとってもマイナスにしかならないと思います。 あるいは、「名前」などを除いたレビューデータが簡単にダウンロードできるようになっていればいいのにと思ったりもします。 【参考ページ】:「AmazonのレビューデータをRとExploratoryでスクレイピングしてみた」(https://qiita.com/A_KI/items/6863d158b9c938055f5a) 【参考ページ】:「stackoverflow」:Inputting NA where there are missing values when scraping with rvest】(https://stackoverflow.com/questions/45901532/inputting-na-where-there-are-missing-values-when-scraping-with-rvest) ☆関連記事 ▼JPRiDEの新モデル・完全ワイヤレスイヤホン「JPRiDE TWS-520」のアマゾン・カスタマーレビューのテキストを分析 ▼「JPRiDE」ブランドのワイヤレスイヤホン「JPRiDE 708」の楽天市場のレビューのテキストを分析:ReviewMetaでアマゾンのカスタマーレビューの信頼性の高さを推定できるJPRiDEの製品 ▼雑誌など第3者の高評価をアピールしている「JPRiDE(ジェイピー・ライド)」ブランドのワイヤレスイヤホン「JPA2」の楽天市場のレビューのテキスト分析です ▼JVCケンウッドの高評価イヤホン「HA-FX3X」とソニーの「MDR-EX450」のカスタマーレビューを比較 ▼3000円クラスの高評価イヤホン「HA-FX3のカスタマーレビューのテキスト分析を「User Local」の「AIテキストマイニング」で行ってみました:こんな分析ツールがあったとは、驚きです ▼カスタマーレビュー分析で、Microsoft Power BIの「Word Cloud」とスライサーの組み合わせは便利です:3000円クラスで、高評価のイヤホン「HA-FX3X」のカスタマーレビューのテキスト分析 ▼アマゾンのカスタマーレビューを購入の判断材料にする場合、「ReviewMeta」(レビューメータ)によるチェックが役立ちます ▼先日購入したイヤホン「HA-FX3X」のアマゾン・カスタマーレビュー分析:低音の良さ、コスパなどが高評価の理由のようです:3000円クラスで、高評価のイヤホンです お気に入りの記事を「いいね!」で応援しよう
Last updated
2019.10.09 07:47:49
コメント(0) | コメントを書く
[データ分析] カテゴリの最新記事
|
|
![[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]](https://hbb.afl.rakuten.co.jp/hgb/18c0b2f0.c9791c8f.18c0b2f1.b0422fd2/?me_id=1213310&item_id=16734639&m=https%3A%2F%2Fthumbnail.image.rakuten.co.jp%2F%400_mall%2Fbook%2Fcabinet%2F6532%2F9784873116532.jpg%3F_ex%3D80x80&pc=https%3A%2F%2Fthumbnail.image.rakuten.co.jp%2F%400_mall%2Fbook%2Fcabinet%2F6532%2F9784873116532.jpg%3F_ex%3D128x128&s=128x128&t=picttext "[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]")
![[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]](https://hbb.afl.rakuten.co.jp/hgb/18c0b2f0.c9791c8f.18c0b2f1.b0422fd2/?me_id=1213310&item_id=18827663&m=https%3A%2F%2Fthumbnail.image.rakuten.co.jp%2F%400_mall%2Fbook%2Fcabinet%2F8147%2F9784873118147.jpg%3F_ex%3D80x80&pc=https%3A%2F%2Fthumbnail.image.rakuten.co.jp%2F%400_mall%2Fbook%2Fcabinet%2F8147%2F9784873118147.jpg%3F_ex%3D128x128&s=128x128&t=picttext "[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]")



