|
|
|
|
2020.05.10
テーマ:医療・健康ニュース(3952)
カテゴリ:データ分析
新型コロナウイルス対策のために検査能力を高める必要があるという理由は、いくつかありますが、最もシンプルな理由は、「早期発見、早期ケア開始のため」ということなのではないかと思います。
「陽性率7%以下」になるように検査数を拡大すべき理由は、感染者を早期に発見できるようにすることなのではないかと思います。 ダッシュボードで、いろいろとグラフを作成していますが、下図は感染確認者数と死亡者数の関係をわかりやすく表していると思います。 以下の内容の一部は、すでに4月17日のブログでも記していますが、散布図のデータを追加して、新たにまとめ直しました。 新型コロナウイルスによって、死亡に至るまでは、「感染→発症→感染確認→入院」といったプロセスを経ている場合が多いと思います。 感染確認者数の山から、遅れて死亡者数の山が見られるのは、上記のような死亡に至るプロセスがあるからです。 重症化してから入院する場合と、ある程度軽症のうちに入院する場合とでは、その後の経過は異なる可能性が高いと思います。 ある程度重症化してからしか検査が受けられないような状況では、死亡のリスクが高くなるはずです。検査のタイミングが遅いと死亡率を高めるのではないかと思います。 特に、高齢者や疾患のあるハイリスクの人は、早期に検査を受けられるようにする必要があると思います。 ECDCのデータを利用したダッシュボードで、感染確認者数の時系列推移と死亡者数の時系列推移のグラフを作成すると、感染確認者数の山の後に死亡者数の山が見られることがはっきりとわかります。 ただし、このような二つの山がはっきりとしているかどうかは、国によって、あるいは感染拡大のフェーズによって異なっているようです。 感染確認者数の時系列推移と死亡者数の時系列推移のタイムラグは、検査が適切なタイミングでできているのかどうかをうかがい知る一つの指標になるのではないかと考え、R言語のccf関数を使って、国別に相互相関を計算してみました。 どれくらいの日数のタイムラグの場合に相互相関が最大になるのかを計算した結果では、ドイツは、比較的長い日数のタイムラグが見られます。つまり、ドイツでは感染確認から死亡までの日数が長いようです。感染確認者に対する治療の時間が確保されているのではないでしょうか。 一方、タイムラグが短い国の場合は、感染確認から死亡までの日数が短いと考えられ、「検査のタイミングが遅い」「医療崩壊によってケアができていない」といったことがあるのではないでしょうか。 日本の場合は、以前はタイムラグが短かったのですが、最近は長くなっています。 日本のグラフを見ると、検査のタイミングが4月上旬頃から改善されてきているように思います。ということは、4月上旬までに発症した人の中には検査体制の制約の影響で、検査のタイミングが遅れて、十分なケアを受けられずに死亡した人が少なからずいた可能性があると思います。もしかすると、有名な俳優の方もその中に含まれていた、ということなのかもしれません。 少なくとも、4月上旬までは、検査のタイミングが遅い場合が直近よりも多かったことがうかがえます。 感染確認者数が減少傾向になった日本では、最近、検査のタイミングが早くなってきているのではないかと思います。 4月初め頃までは、検査のキャパがひっ迫していたようです。諸外国と比べて、少なかった検査数は、死亡者数の増加につながった可能性があるのかもしれません。 検査数に余裕がないと、ケアの開始が遅くなることによって、死亡率の上昇につながりかねないので、今後も検査能力の拡充が望まれます。 ↓ECDCデータ版のダッシュボードで、国別に感染確認者数の時系列と死亡者数(右目盛り)の時系列を並べて見ることができます。 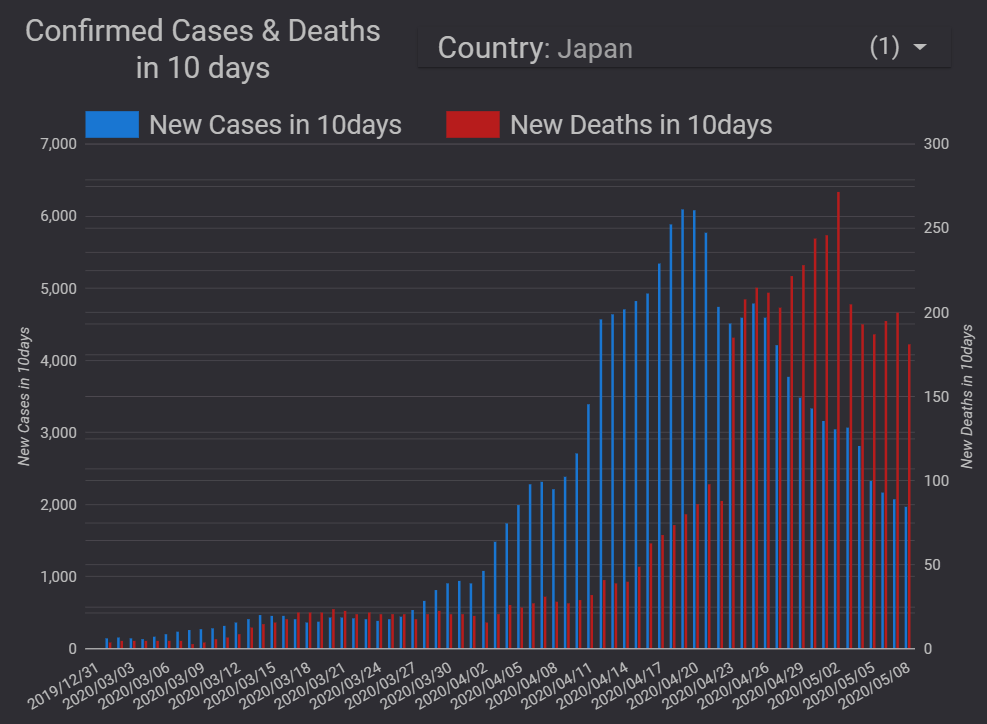 ↓下図は直近の相互相関の計算結果ですが、日本の「感染確認者数の時系列と死亡者の時系列」は、11日間のタイムラグの場合に相関が最大になっています。4月17日に計算した結果では、4日間でした。 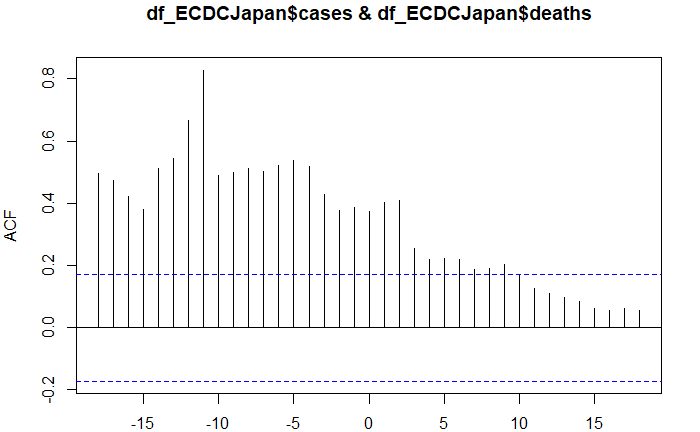 ↓4月17日のブログで紹介したグラフです。4日間のタイムラグの場合に相関が最大になっています。 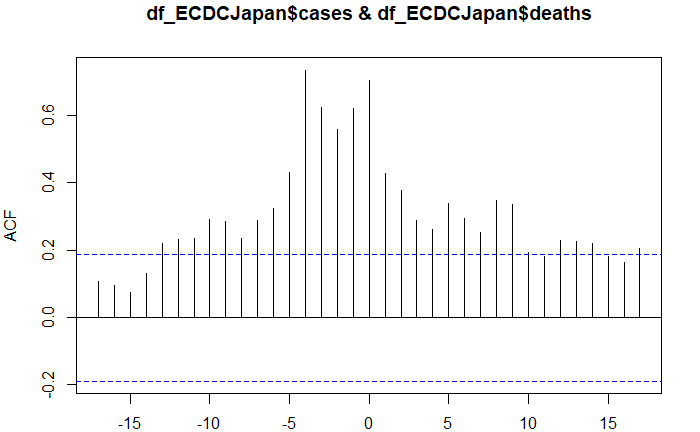 ↓感染確認者数の時系列推移と死亡者数の時系列推移の相互相関を国別に計算しました。相関が最大になる「lag(タイムラグ)」(横軸)と死亡率(縦軸)をプロットしています。累積死亡者数が50人以上で、タイムラグが0未満の国についてプロットしています。タイムラグの日数が長い国の方が死亡率がやや低い傾向が見られます。 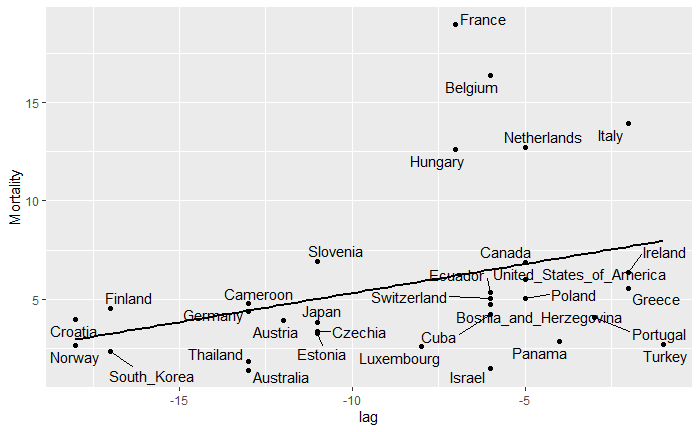
【散布図を作成するためのRのコード例】 実効再生産数・Rtの計算で用いたループの手法で、国別にccf()関数の計算をしてみました。リストに対してループ処理ができるので便利です。 ----------------------------------------------------------------- --------------------------------------------------------------------------df_ECDC <- read.csv("https://opendata.ecdc.europa.eu/covid19/casedistribution/csv", na.strings = "", fileEncoding = "UTF-8-BOM",stringsAsFactors = FALSE) geo_list <- unique(df_ECDC$countriesAndTerritories) df_ECDCtemp1 <- NULL df_ECDCtemp <- df_ECDC df_CC <- NULL cc_temp <- NULL cc_tempmr <- NULL dfcc_tempmr <- NULL dfcc_tempmrmax <- NULL for (i in seq_along(geo_list)) { df_ECDCtemp1 <- subset(df_ECDCtemp,df_ECDCtemp$countriesAndTerritories==geo_list[i]) cc_temp <- ccf(df_ECDCtemp1$cases, df_ECDCtemp1$deaths,plot=FALSE) cc_tempmr <- matrix(c(cc_temp$lag,cc_temp$acf),ncol=2) dfcc_tempmr <- as.data.frame(cc_tempmr) colnames(dfcc_tempmr) <- c("lag","acf") dfcc_tempmrmax <- dfcc_tempmr %>% slice(which.max(acf)) dfcc_tempmrmax <- mutate(dfcc_tempmrmax,countriesAndTerritories=geo_list[i]) Confirmed_M <- max(df_ECDCtemp1$Confirmed) Deaths_M <- max(df_ECDCtemp1$C_Deaths) Mortality <- Deaths_M/Confirmed_M*100 dfcc_tempmrmax <- mutate(dfcc_tempmrmax,Confirmed=Confirmed_M) dfcc_tempmrmax <- mutate(dfcc_tempmrmax,Deaths=Deaths_M) dfcc_tempmrmax <- mutate(dfcc_tempmrmax,Mortality=Mortality) df_CC <- rbind(df_CC,dfcc_tempmrmax) } df_CCd1 <- subset(df_CC,df_CC$Deaths >= 50) df_CCd2 <- subset(df_CCd1,df_CCd1$lag < 0) ggplot(df_CCd2,aes(x=lag,y=Mortality,label = countriesAndTerritories)) + geom_point()+stat_smooth(method = "lm", se = FALSE, colour = "black", size = 1) + geom_text_repel() -------------------------------------------------------------  ↓実効再生産数を計算できるWebアプリがあります。 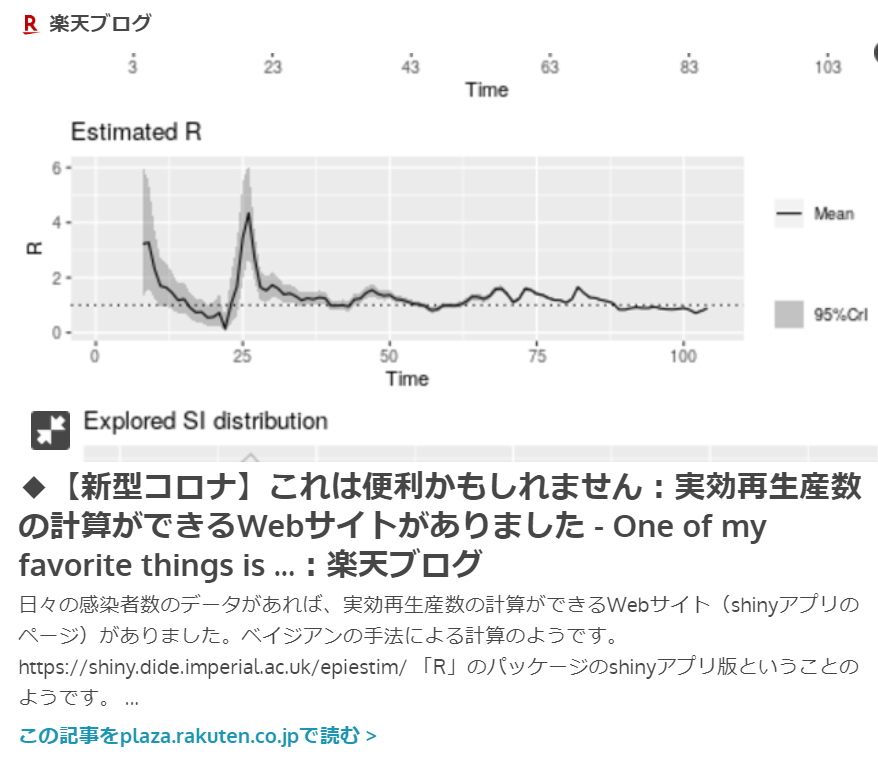 ↓倍加時間についてです。  -------------------------------------------------------------------------- 
【ダッシュボード「COVID-19 Transition Graphs」を試作】 中国本土以外の地域への感染が拡大しているため、国別、地域別の感染者数の推移を簡単に確認できるダッシュボードを試作しています。 随時、ページを追加しています。グラフのデータは、右上部分の操作でダウンロードすることができます。 アメリカの「地域別の変数」を前処理して、「州別」での推移をグラフ化できるようにしました。 また、州コードのフィールドを作成してコロプレス地図も作成しています。 楽天ブログでは「iframe」タグが使えないので、Bloggerのページから利用できるようにしています。 無料で利用できる、グーグルの「データポータル」のダッシュボードです。データさえあれば、簡単に作成できます。「国」別、「地域」別に日ごとの感染者数の推移を見ることができます。 ↓ダッシュボードの試作です。下記リンクのページから利用できます。  ジョンズ・ホプキンス大学の「JHU CSSE」の「Covid19 Daily Reports」のデータを利用しています。 直近のアメリカのデータは地域分類が細かくなっていて、1日当たり2千行くらいになっています。 EdgeブラウザやIEブラウザなど、Chromeブラウザ以外での利用の場合はうまく表示されないことがあるようです。 新型コロナウイルス(2019-novel coronavirus)対策もインフルエンザ対策と同じで、手洗い、うがい、マスク着用(咳エチケット)、免疫力アップなどが対策になるようです。↓上記のダッシュボードのデータの出所のサイトです。マップがメインのダッシュボードです  ----------------------------------------------------------------------------------------- ↓WHOのサイトでも、感染者数、地域などの「Situation Report」が日々更新されています。関心がある場合は、一日に一度見るといいのではないかと思います。   ↓日本のインフルエンザの「定点当たり報告数」をグラフ化できるダッシュボードを試作。都道府県別にグラフ化可能です。 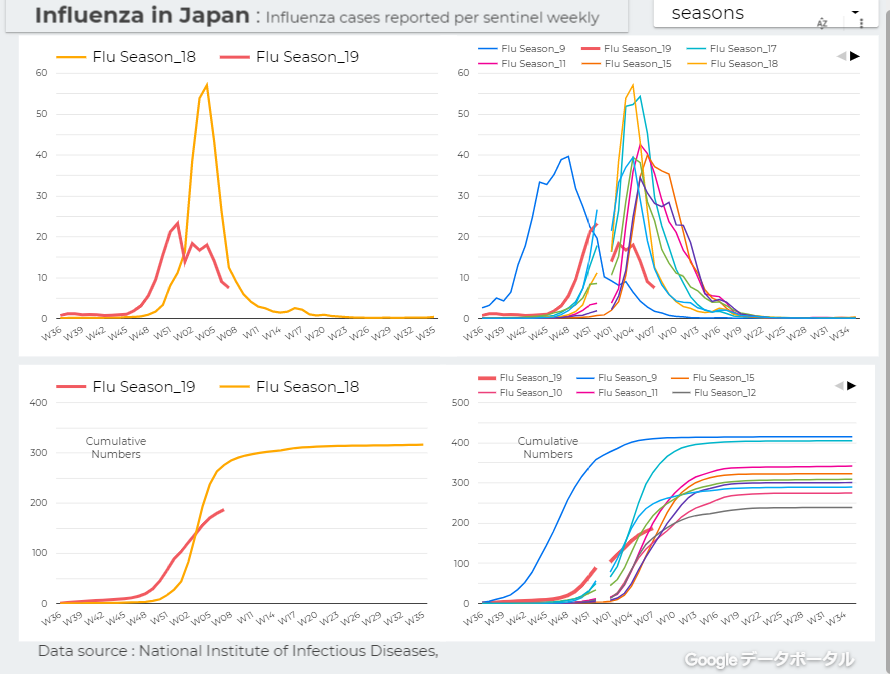 ------------------------------------------------------ ---------------------------------------------------------------------------- ★おすすめの記事     ◆How Windows Sonic looks like.:Windows Sonic for Headphonesの音声と2chステレオ音声の比較:7.1.2chテストトーンの比較で明らかになった違い:一目で違いがわかりました  ---------------------------------------------------------------------------------------------------------- お気に入りの記事を「いいね!」で応援しよう
[データ分析] カテゴリの最新記事
たいへん有意義な統計グラフィックスをご提供くださり、ありがとうございます。
日毎の疾病発見数と、死亡数を並べて表示し、タイムラグを見せる(診る)手法は とても素晴らしいと思いました。 二つのピークの時間差は、その国(地域)が、疾病の勢いに対応できているかを表現していて、 左右のY軸のスケールの違いが、凡その死亡率のスケールを反映していますね。 日本では、二つのピークが、時間差をもって、平行移動しているけれど、 USAでは、死亡数のピークが疾病発生数に追いつき追い越してしまい、社会が対応できなくなった(いわゆる医療崩壊)様子を表現していると感じました。 私は、最近やっと、統計の勉強を始めた医師です。 Rを使って勉強しています。 ggplot という grammar of graphics という意味で、graphics には exploratory とexplanatoryの役割がある、ということを知りました。 このグラフこそ、まさにそれだと思いました。 ありがとうございます。 (2020.05.12 03:37:55)
PCR検査数の指標として、人口あたり検査数と、診断確認例数あたり検査数(陽性率の逆数)が問題となります。陽性率は 疾病流行の勢いと、医療側の検査能力の拮抗で出てくる、検査が充分に行われているかの指標で、これがあるレベル以下であることが望ましい。
陽性率が一定数値以下で、病床占有率が一定以下で、人口当たり時間あたり発生数が一定数値以下である、という指標により、地域が、疾病の流行に対応できているかが表現されると思いました。 Our World in DATA では x軸に人口あたり患者数 y軸に人口あたりPCR検査数、斜めの点線で診断確認数あたり検査数を表現しています。 このサイトを専門家会議の報告でも引用していました。 https://ourworldindata.org/grapher/covid-19-tests-cases-scatter-with-comparisons (2020.05.12 04:19:28)
Tetsuo Kimuraさんへ
ありがとうございます。 何かのご参考になれば幸いです。 グラフなど、すべてご自由にご利用ください。 といっても、データはECDCのものですが。ECDCはそのページに、csvデータ読み込み用の「Rのコード」を記載しているくらいなので、自由に利用していいのだと思います。どこかの国や世界的組織は、データをPDF形式でしか公表していなかったりして、「オープンデータ」を本気で考えていないことがわかります。 「陽性率7%」の千葉大の論文では、タイムラグについても言及していたので、Our World in DATAのデータも使って、タイムラグと検査数について何か分析できないかと、考えています。死亡率との関係では、タイムラグの方が直接の関連性が高いのではないかと思います。 私は、データビジュアライゼーション、統計分析の勉強を、主に「R」でしていますが、kaggleでは大多数がPython派なので、Pythonも始めようかと考えています。でも、用途によってはできることはRとほとんど同じだったりします。 (2020.05.12 05:48:35) |
|
![[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]](https://hbb.afl.rakuten.co.jp/hgb/1ae15073.43ba9030.1ae15074.eb6248a2/?me_id=1222042&item_id=10024456&m=https%3A%2F%2Fthumbnail.image.rakuten.co.jp%2F%400_mall%2Fandit%2Fcabinet%2Fitem%2Fmask%2Fand-h202018a.jpg%3F_ex%3D80x80&pc=https%3A%2F%2Fthumbnail.image.rakuten.co.jp%2F%400_mall%2Fandit%2Fcabinet%2Fitem%2Fmask%2Fand-h202018a.jpg%3F_ex%3D240x240&s=240x240&t=picttext "[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]")

![[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]](https://hbb.afl.rakuten.co.jp/hgb/1aae7a85.f4143c83.1aae7a86.7dc201df/?me_id=1210867&item_id=10054198&m=https%3A%2F%2Fthumbnail.image.rakuten.co.jp%2F%400_gold%2Fgoodlifeshop%2Fgcabi%2Fbct%2F4903320575981.gif%3F_ex%3D80x80&pc=https%3A%2F%2Fthumbnail.image.rakuten.co.jp%2F%400_gold%2Fgoodlifeshop%2Fgcabi%2Fbct%2F4903320575981.gif%3F_ex%3D240x240&s=240x240&t=picttext "[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]")



