|
|
|
|
Nov 21, 2010
カテゴリ:「VB.NETで自動売買」入門
前回から間を置かずに<その3>を投稿する事は私自身も予定していませんでした。
ログイン処理が出来たら、皆さんが知りたいのは恐らく注文処理と一覧取得処理だと思います。 注文処理は、クリック証券のWebサービスのように容易にはいきません。 SBI証券バックアップサイトは発注を行う時に2画面に渡って行います。つまり、 HTTPリクエストを2度送信して初めて発注出来ます。 また、その間処理がシーケンシャルに行われているか判断するために隠しパラメータを 使用しているので、悩んでいる方もいらっしゃるかと思います。 保有銘柄一覧や注文一覧など、一覧情報の取得に悩まれている方もいらっしゃるでしょう。 こちらは、HTMLソースから繰り返し情報を効率良く取得するにはどうするかというのが ポイントになってくると思います。 それら2つのメイン処理は次回以降に回すとして、その予備知識として先に 「正規表現」というものを扱いHTMLソースから効率良くデータを取得する方法をご紹介します。 作成する処理はクリック証券編と同様、購買余力の取得です。 クリック証券編<その6>に書いているように「余力確認」ボタンを作成し、 コードの実装を行う準備をして下さい。 どんなURLを送信しないといけないかは、実際のSBI証券バックアップサイトで確認します。 Webブラウザを使ってログインすると、トップページに「買付余力」というリンクがあります。 トップページのHTMLソースを見て「買付余力」と書いているリンク(Aタグ)に書いてある URLを確認しても構いません。でもソースを見慣れていない人はややこしいですし URLも相対パスで書いているので分かりにくいです。 そこで、簡単な方法があります。 実際に「買付余力」リンクをクリックし、買付余力画面を表示して下さい。 その時WebブラウザのURLに表示されているのがそれです。 ※もしWebブラウザでURLの表示をしていない場合はブラウザのオプションから表示して下さい ちなみに買付余力の確認には何のリクエストパラメータも要りません。 よって、ログイン処理の時と同様にソースを書くと、このようになります。 Dim res As WebResponse = HttpPost("https://k.sbisec.co.jp/~~/purchaseMarginList.do", "") Dim html As String = "" Using sr As New IO.StreamReader(res.GetResponseStream, Encoding.GetEncoding(932)) html = sr.ReadToEnd() End Using これで、変数「html」には応答HTMLソースが返って来ています。 問題はここからです。そのHTMLソースから、どうやって買付余力を取得するかです。 例えば私の買付余力画面はこのようになっています(お恥ずかしい)。 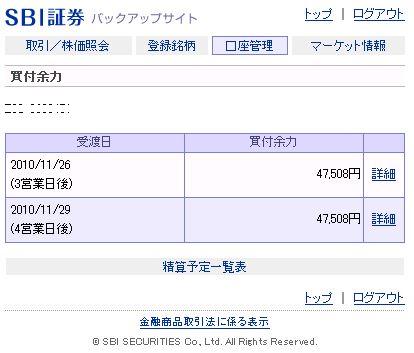 人間が見れば「47,508円だな」と分かりますが、プログラムからこの金額を 取得するには果たしてどうしましょうか。 Webサービスの応答のように「ここに金額が入っていますよ」と示すタグもありません。 せいぜい、単に表を構成するTABLEタグぐらいでしょう。 入力項目(テキストボックス等)ではなくただの表示項目なので、特にそこを データとして識別するものは何もありません。 しかも、金額は複数箇所にあります(^^; 取得したいのは一番上にある金額です。 こんな時、テキスト文字列を解析するのに非常に役立つのが「正規表現」です。 私が解説するよりも、もっと良いリソースがネット上に沢山ありますので、 ご存じない方は是非このキーワードで検索して頂ければ幸いです。奥が深いです。 .NET Frameworkで正規表現を扱うには「System.Text.RegularExpressions.Regex」というクラスを使用します。 このクラスには、文字列から自分の指定した文字列パターンに合致するものを 検索する「Match()」というメソッドがあり、それを使用します。 申し訳ないですが、まずはソースをご紹介します。 Dim m As Match = Regex.Match(html, "<td\salign=""right"">\s*(?<yoryoku>\S*)円") このように「Regex」というクラスをコーディングするには、ソース上部に Imports System.Text.RegularExpressions が必要です。 あるいは「System.Text.RegularExpressions.Regex」とフルで書いて下さい。 上のソースのポイントはダブルクォーテーションで囲まれた部分です。 少しだけ解説すると、文字列中の「""」は、一番外側のダブルクォーテーションとは違い、 文字列中の「"という文字」という風に扱うものです。2つ続けて記述します。 「\s」は半角スペースを意味します。「*」は、0回以上繰り返すという意味です。 「?<yoryoku>」は、その位置にある文字を「yoryoku」という変数として定義しています。 つまり、上の文字列は、HTMLソースの中から、一番最初に見付かった 「<td align="right"> xxxxxx円」という文字列パターンを探します。 「xxxxxx」の部分の長さは言及していません。また、その左のスペースの長さも。 スペースが終わって何か違う文字列が入っている部分(「円」が出現する手前)である「xxxxxx」の 部分を変数「yoryoku」という名前で定義します。 この結果の変数「m」を使って余力を取得します。 m.Groups("yoryoku").Value が求めている値です。 メッセージボックスで出力するために以下のように書きます。 「Groups」なんて書いてますので、もし指定したパターンに合致する場所が複数箇所存在する 場合は「yoryoku」は複数あります。今回もそうですね。 ですが、上の1行だけだと、最初に見つかったものしか取得していません。 複数回の取得方法は一覧情報を取得する回に解説させて頂きます。 MessageBox.Show("購買余力は" & m.Groups("yoryoku").Value & "円です。") いかがでしょうか? これで、HTMLソースから何とかデータを取得する事が出来そうですよね。 最終的にソースはこうなりました。 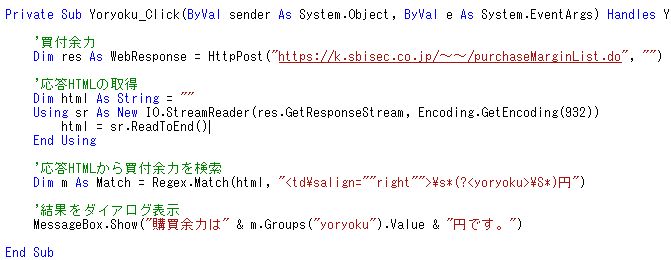 正規表現についてあまり理解されていない方は、次回までに学習される事をお勧めします。 Webスクレイピングのために有効な知識ですので損は無いと思います。 お気に入りの記事を「いいね!」で応援しよう
[「VB.NETで自動売買」入門] カテゴリの最新記事
|

 KNIGHT@
KNIGHT@



