|
|
|
|
2017年07月14日
カテゴリ:株、投資
udemyの以下の講座に株価予測の内容があったので、ちょっと改造してそれを10年間の日経平均株価に適用してみた。
https://www.udemy.com/learning-ai/learn/v4/content 連続4日間の値動きから5日目の上がり(1)、下がり(0)を予測する。 期間:2007.7.13〜2017.7.13 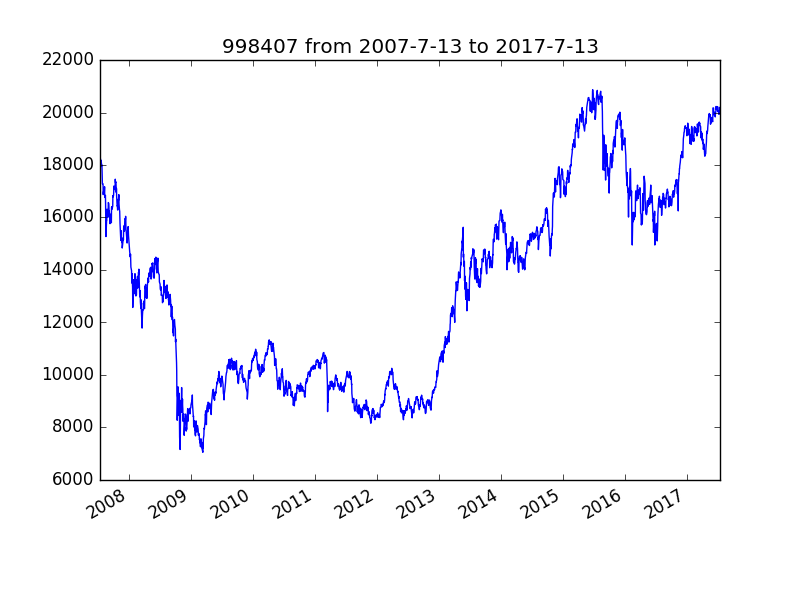 使ったコード (python3対応、インデントが壊れている) ----- import pandas as pd from sklearn import svm # ファイルの読み込み df=pd.read_csv("998407 from 2007-7-13 to 2017-7-13.csv", header=None) # 株価の上昇率を算出、おおよそ-1.0-1.0の範囲に収まるように調整 modified_data = [] for i in range(1, len(df)): modified_data.append((df[1][i] - df[1][i-1])/float(df[1][i-1]) * 20) # 前日までの4連続の上昇率のデータ successive_data = [] print("正解値 価格上昇: 1 価格低下: 0") answers = [] for i in range(4, len(modified_data)): successive_data.append([modified_data[i-4], modified_data[i-3], modified_data[i-2], modified_data[i-1]]) if modified_data[i] > 0: answers.append(1) else: answers.append(0) print("データ数") n = len(successive_data) print(n) m = len(answers) # print m # 線形サポートベクターマシーン clf = svm.LinearSVC() print("サポートベクターマシーンによる訓練 (データの最初の75%を訓練に使用)") print(int(n*75/100)) clf.fit(successive_data[:int(n*75/100)], answers[:int(n*75/100)]) print("テスト用データ (データの最後の25%をテストに使用)") print(int(n*25/100)) # 正解 expected = answers[-int(n*25/100):] # 予測 predicted = clf.predict(successive_data[-int(n*25/100):]) print("末尾の10個を比較") print(expected[-10:]) print(list(predicted[-10:])) # 正解率の計算 correct = 0.0 wrong = 0.0 for i in range(int(n*25/100)): if expected[i] == predicted[i]: correct += 1 else: wrong += 1 print("正解:",correct) print("テストデータ数:",int(n*25/100)) print("正解率: " + str(correct / (correct+wrong) * 100) + "%") ----- ↓実行結果 正解値 価格上昇: 1 価格低下: 0 データ数 2446 サポートベクターマシーンによる訓練 (データの最初の75%を訓練に使用) 1834 テスト用データ (データの最後の25%をテストに使用) 611 末尾の10個を比較 [0, 1, 0, 1, 0, 0, 1, 1, 0, 1] [1, 1, 1, 1, 1, 1, 1, 1, 1, 1] 正解: 328.0 テストデータ数: 611 正解率: 50.90016366612111% >>> 正解率がほぼ50%ということは、まったく役に立たないということだ。 もっと工夫が必要ということだな。。 にほんブログ村 お気に入りの記事を「いいね!」で応援しよう
|