|
|
|
|
全て
| 全く分類できないもの・・・
| ギルド関係メイン
| 祭り関係
| RS関係(未分類に近い)
| ネタみたいなもの・・・
| 旅行
| クイズ大会&替え歌♪
| 露店
| (ネタ)考察関係
| ショートコント
| 1ゲト祭り?
| ぷよぷよ
| ソニック
| 麻雀
| 初心者向け
| 上級者向け
| REDSTONE2
| ウェザーロイド
| サーバ
| 御伽原江良
| ウマ娘
| youtube
| かいもの
| 将棋
2022.10.12
テーマ:パソコン相談室(484)
カテゴリ:サーバ
pythonでwebスクレイピングをするときに以下のようなコードを書くことがあるかと思います。
今回はこのコードを書いた時にハマった話を紹介。
※headersには適切な仮のヘッダ内容が指定されているものとします。 ※対象のwebページはshift-jisなので、文字コードも想定通りの挙動とします。 (他PCにてその他のプログラムは動作確認済み) ※windows10, 11環境で検証
ぱっとみ、普通にwebページからソース拾ってきて内容をbs4(BeautifulSoup)で拾ってきそうに見えるコードですが… 実際には上記実装をするとかなりの環境依存なコードになります よくある解決法として、apparent_encodingを指定するというものがあります。
こう書くことでchardetライブラリが自動判定された文字エンコーディングで内容をデコードしてくれます。 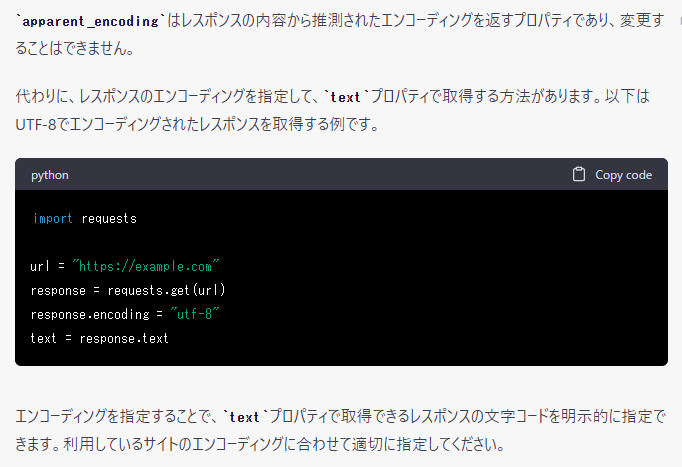
そこで、こう直してみるも文字化けする状況は改善せず。
文字コードに何が指定されているんだこれ、と思って調べてみたところ、 response.encodingとresponse.apparent_encoding にGB18030が指定されていたのであった…。 初めて聞く文字コード、どこのだこれ?と思ってググってみた。
WikiPedia ・・・???
ボクノパソコン、ドコシュッシンナノ とはいえapparent_encoding は@propertyよろしくset不可なフィールド(=こいつに変数を代入することはできない) 直接文字コードを指定しても文字化けするのはなぜ…? 原因はここにありました。
ここをres_bs = response.textにすると直ります。 デバッグで中身を見てみると、contentの方は\x86\x80...みたいなバイトコードで文字の部分が記載されており、textのほうはencoding指定のものでエンコード済みのテキストで記載されています。 どちらにせよBeaultifulSoupのfrom_encoding="shift-jis"でorigin_encodingをSJISに上書きするかのように見えますが、実際には全然異なった。 BeautifulSoupがcontentに対して最初に参照する文字コードはapparent_encodingであったのだ… ※4.10現在 つまり、 (1) requestsでsjisのエンコードでソース取得 (2)PC側のデフォルドエンコードをshift-jisで強制的に変更 (3)contentはエンコード前の文字列。textはエンコード後の文字列 (4)Bs4はcontentを指定されるとapparent_encodingを参照してコンテンツをデコードをし、その後にfrom_encodingを実施 というステップを踏んでいることがわかった。 bs4のorigin_encodingは変更不可っぽそうなので今回はcontentを取得していたところを諦めてtextで取得するように改修して無事文字コード問題を解消した。 なので、requests->bs4にデータを渡すときはcontentでなくtextで渡した方が文字コード問題を起こさずできますよ、って話でした。 ちなみに上記コードを実行するとbs4の部分でwarningが出ます。 文字コード指定しすぎだよ、と。 確かにこの方法だとfrom_encodingが不要になるのでコードから消して解決。 これでwarning出すことなく無事動きました。
最近、chatGPTにきいても原因わからずな話はこうやって記事にしておくのアリかなと思ってる。 (chatGPT使ってトラブルシュートすると一定の会話量超えるとゲームのNPCみたいに会話がループし始めて永遠と問題解決しないことがあるので…。そういう場合は視点変えて聞き方変えるのが有効策だったりする。) お気に入りの記事を「いいね!」で応援しよう
Last updated
2023.03.12 10:02:15
コメント(0) | コメントを書く
[サーバ] カテゴリの最新記事
|




