|
|
|
|
2019.08.09
カテゴリ:家電・ガジェット
先日、購入したJVCケンウッドのイヤホン、「HA-FX3X」のアマゾンのサイトでのカスタマーレビューのテキストを分析しています。
どこで購入するにしても、アマゾンのカスタマーレビューが役立つ場合があると思います。 イヤホンの音についての評価は、聴力や音の好み、聴く音楽のジャンルなど、個別的、主観的な要素が多いので、一個人の感想・評価はあてになりません。 できるだけ多くの人の評価を俯瞰して傾向をつかむことが役に立つと思います。 レビューのテキスト分析から、「HA-FX3X」が、どのような評価を得ているのかがわかってきます。 「HA-FX3X」のレビュー件数は、1,039件と多いので、レビューの内容を要約するために、テキストマイニングの手法を用いました。  まず、アマゾンのカスタマーレビューをすべてスクレイピングしましたが、レビューの「☆☆☆☆☆」の評価、購入した色などの情報もすべてスクレイピングできているので、とりあえずMicrosoft Power BIにデータを取り込みました。  アマゾンのレビューでの評価は、アマゾン独自の評価方法があるらしく、「3.9」となっていますが、単純平均では、4.04となっています。「☆が5個」の評価者は、1,039人中の543人となっています。 レビューしている人が購入した「HA-FX3X」の色では、「ブラック」(481)、「クリムゾンレッド」(314)、「ステルスブラック」(244)の順になっていて、「ブラック」が最も多くなっています。 Power BIに追加できるカスタムビジュアルに、「ワードクラウド」があったので、レビューの本文ではなく、「見出し」部分を表示させてみました。「重低音」「低音最高」「お気に入り」「普通です」「偽物に注意」といった単語が目立っています。 スクレイピングしたデータを、テキストマイニングソフトの「KH-Coder」で読み込み、「見出し」に出てくる単語の頻度を見てみました。 「良い」「音」「低音」「最高」「重低音」「音質」「コスパ」などの単語が見出しに多く使われていることがわかります。 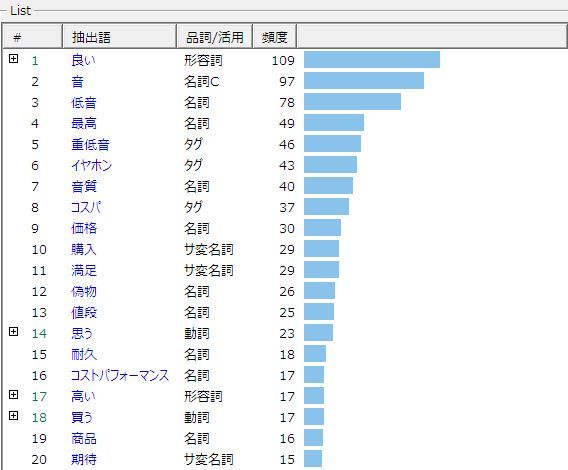 「☆の個数」と見出しの単語の組み合わせを、「対応分析」で見ると、右上にある「☆5個」と「価格」「コスパ」「重低音」といった単語が近い距離にあります。高い評価の背景には、「コストパフォーマンス」や「重低音」への評価があるようです。 なお、左上の「☆1個」の近くには、「偽物」という単語が近くにあり、「偽物」への評価が低評価と関連していることがうかがえます。 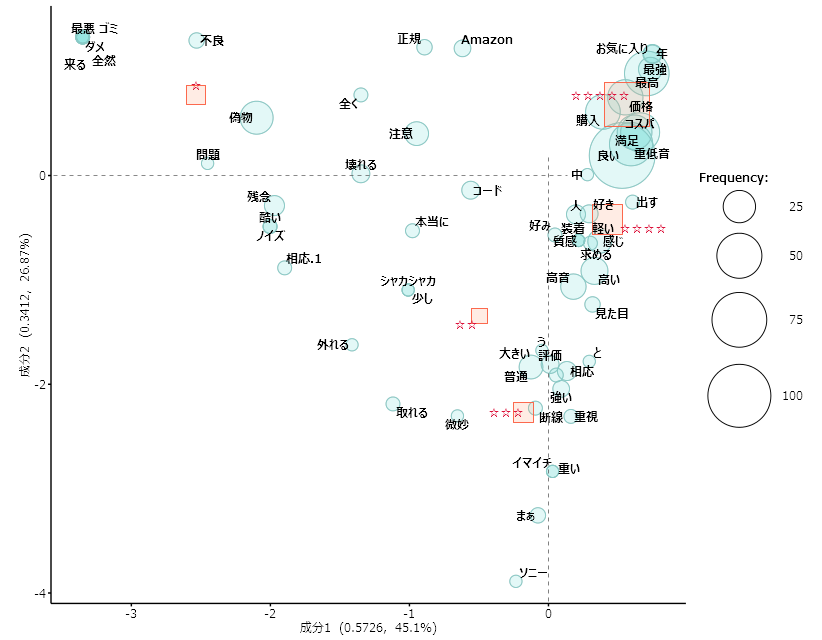 ▼テキスト分析は、データの前処理が膨大になりそうです 「R」でアマゾンのレビューをスクレイピングできるということで、ネットの情報を基にレビューの情報をスクレイピングできました。 スクレイピング自体は、ネットで紹介されていたRのコードをRStudioにコピペして、必要な部分を修正するだけでできましたが、RからCSVファイルへの書き出しの際に、一部エラーが起きました。 文字列中のカンマの誤認だけならいいのですが、「‼︎ 」などの特殊記号や絵文字が英数字の表記になったりしました。特殊記号や絵文字は、今回のテキストマイニングには不要の情報ですが、できればエラーはない方がいいと思います。 Rのコマンドによる「書き出し」を研究中です。文字コードの処理法などをいろいろと検討する必要がありそうです。テキスト分析は、膨大な前処理を必要とするようです。 RStudio Source Editorに表示されたスクレイピング結果をExcelシートにコピペする方法であれば、文字化けなどのエラーが一切なかったので、仕方がないので、1039件分のデータを何回にも分けて、RStudio Source EditorからExcelシートにコピペしました。 ※参考サイト:「AmazonのレビューデータをRとExploratoryでスクレイピングしてみた」(https://qiita.com/A_KI/items/6863d158b9c938055f5a) HA-FX3X : 公式の製品情報ページ お気に入りの記事を「いいね!」で応援しよう
Last updated
2019.08.11 16:38:12
コメント(0) | コメントを書く
[家電・ガジェット] カテゴリの最新記事
|
|
![[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]](https://hbb.afl.rakuten.co.jp/hgb/18c0ee06.b6ecb353.18c0ee07.31d00a5a/?me_id=1345086&item_id=10000173&m=https%3A%2F%2Fthumbnail.image.rakuten.co.jp%2F%400_mall%2Fkotosquare-jvckenwood%2Fcabinet%2Fjvcheadphone01%2Finnerear01%2Finearxx%2Ffx3xsam.jpg%3F_ex%3D80x80&pc=https%3A%2F%2Fthumbnail.image.rakuten.co.jp%2F%400_mall%2Fkotosquare-jvckenwood%2Fcabinet%2Fjvcheadphone01%2Finnerear01%2Finearxx%2Ffx3xsam.jpg%3F_ex%3D240x240&s=240x240&t=picttext "[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]")




